Почему A/B-тесты уменьшают конверсию
Как отличить иллюзорные результаты от реальных? 10 советов для правильного A/B-тестирования.
Константин Юревич
13 мая 2015
1 824
В Driveback мы постоянно сталкиваемся с необходимостью проведения A/B-тестов для проверки тех или иных гипотез. На проведении многих A/B-тестов настаивают наши клиенты. Нередко мы тратим по несколько часов, чтобы объяснить, почему тот или иной тест делать абсолютно бессмысленно.
В своей практике мы крайне редко встречали маркетологов, которые бы до конца осознавали, как правильно делать A/B-тесты. Хуже того, большинство из них делают тесты абсолютно неправильно!
В этой статье мы постараемся показать, как неправильно проведенные A/B-тесты могут показать превосходные результаты, которые, однако, будут всего лишь иллюзией успеха. В лучшем случае, это приведет к бесполезным изменениям на сайте и потере времени и денег. В худшем — к изменениям, которые в действительности могут повредить конверсии и прибыли.
Базовые понятия
Начать стоит прежде всего с базовых понятий, которые известны каждому математику, но забыты многими новоиспеченными специалистами по модному нынче A/B-тестированию. Это такие понятия как «статистическая мощность», «статистическая значимость», «множественные сравнения» и «регрессия». Понимая эти принципы, вы сможете защититься от дезинформации и заблуждений, которые наводнили индустрию A/B-тестирования, и отличать иллюзорные результаты от реальных.
Статистическая мощность
Статистическая мощность — это всего-навсего вероятность (в процентах) того, что тест определит разницу между двумя вариантами, если эта разница действительно существует.
Предположим, вы хотите определить, есть ли разница между ростом женщин и мужчин. Если вы измерите всего лишь одну женщину и всего лишь одного мужчину, может оказаться так, что вы не заметите того факта, что мужчины выше женщин. Быть может, вам попалась волейболистка и мужчина роста ниже среднего.
Однако, измерив достаточное количество разных мужчин и женщин, вы придете к выводу, что на самом деле мужчины выше. Потому что статистическая мощность увеличивается при увеличении размера выборки.
Абсолютно таким же образом это работает и в применении к конверсии интернет-магазинов и других веб-сайтов. Допустим, мы хотим проверить, увеличится ли конверсия, если интернет-магазин будет давать скидку 10% на определенный вид товаров. Будет ли виден прирост в конверсии, зависит от статистической мощности теста. Чем выше мощность — тем выше вероятность, что вы увидите реальный результат.
В своей практике мы неоднократно сталкивались с ситуацией, когда в первую неделю A/B-теста со значительным перевесом «выигрывал» вариант № 1 (см. изображение 1).
Изображение 1: Результат после 2 дней тестирования и 33 000 посетителей в каждую ветку.
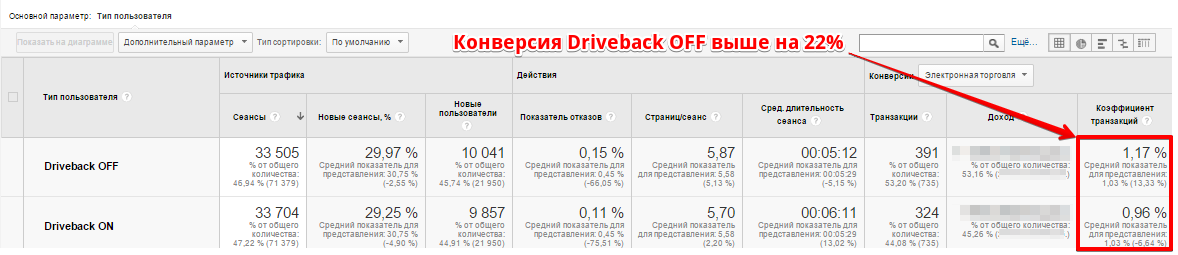
Однако, после достижения достаточной статистической мощности результат выравнивался, и далее уже с абсолютным постоянством выигрывал вариант № 2 (см. изображение 2).
Изображение 2: Результат после 2 недель тестирования и 400 000 посетителей в каждую ветку.
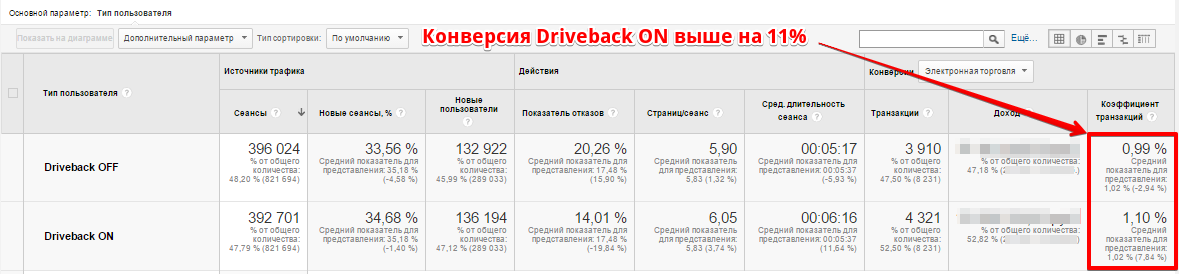
Какой же размер выборки можно считать достаточным?
Достаточный размер статистической выборки напрямую зависит от следующих величин:
- Статистической мощности, которой мы хотим достигнуть.
- Статистической значимости (речь о ней пойдет ниже).
- Величины эффекта (для интернет-магазинов это может быть разница в конверсиях).
Мы рекомендуем не доверять тестам, статистическая мощность которых ниже
Для подсчета оптимального размера выборки можно использовать калькулятор на нашем сайте.
Важно! Размер выборки в каждую ветку A/B-теста необходимо определить еще до начала теста и не менять до его окончания! Ниже мы опишем, почему это крайне важно!
Статистическая значимость
Допустим, A/B-тест был проведен в соответствии с требованиями, описанными выше. Достигнута необходимая статистическая мощность и наконец можно посмотреть на результаты теста. Теперь необходимо определить, является ли тот результат, который показывает тест, статистически значимым. Простыми словами это означает: каков шанс того, что разница видна там, где ее на самом деле нет.
Или еще проще — какова вероятность того, что мы бы увидели подобный результат, если бы вместо A/B-теста проводили A/A-тест (тестирование варианта сайта против себя же самого). Если такая вероятность мала — результаты теста можно считать статистически значимыми. Если она велика — результат может быть чистой случайностью (погрешностью), и ему не стоит доверять.
Мы придерживаемся строгого мнения, что уровень статистической значимости должен быть минимум 95%. Таким образом, шанс увидеть результат там, где его на самом деле нет, — всего 5% (p-value = 5%).
Именно проверка статистической значимости результата помогает определить настоящего «победителя».
Для определения статистической значимости можно использовать множество калькуляторов. Один из них вы можете найти у нас на сайте.
Самая критическая и распространенная ошибка в A/B-тестировании — останавливать тест, как только становится заметно, что один из вариантов побеждает с существенным отрывом. Даже если результат при этом является статистически значимым — это верный путь получить false-positive (ложноположительный) результат!
Как мы уже писали ранее, то, что результат проходит тест на статистическую значимость, не значит, что он верный. Вполне возможно, что он ошибочен, т.к. не достигнут необходимый размер выборки.
Мы понимаем, что крайне сложно удержаться вдали от Google Analytics и подождать месяц, пока тест не будет завершен, не заглядывая в результаты раньше времени. Однако именно это спасет вас от серьезных ошибок!
Это легко проверить, проводя A/A-тест (тестирование одной и той же версии сайта против себя же). Допустим, мы запустили на сайте A/A-тест и проверяем его результаты каждый день, вплоть до завершения, каждый раз останавливая тест в случае достижения статистической значимости (p-value = 5%). Вы увидите, что почти каждый день вы будете получать статистически значимый результат того или иного варианта! И это будет продолжаться до тех пор, пока выборка не станет достаточно большой. Если действовать описанным выше способом в A/B-тесте, 80% ваших результатов будут абсолютной чушью. Только вдумайтесь — 80%!
Рассмотрим важность статистической значимости на одном из реальных примеров. На изображении 3 показан пример результатов A/B-теста одного из наших клиентов. Конверсия варианта DRIVEBACK_OFF составляет 1.47%, конверсия варианта DRIVEBACK_ON — 1.21%. Какой, по вашему мнению, вариант выигрывает?
Изображение 3: Пример результата А/Б-теста, который не является статистически значимым.
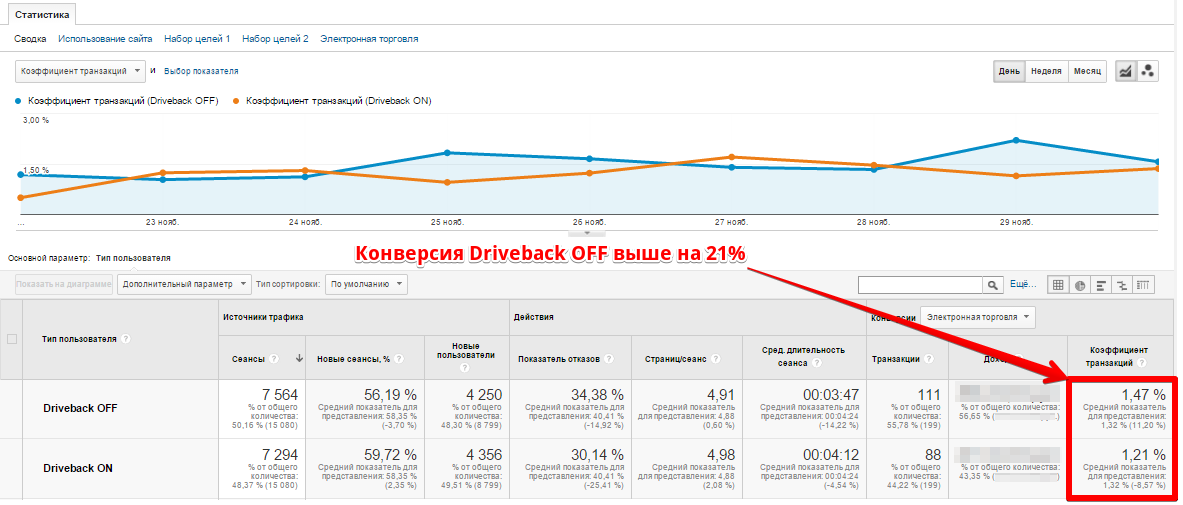
Предполагаем, вы убеждены, что вариант DRIVEBACK_OFF лучше. Вы будете удивлены: на самом деле это результаты не A/B-теста, а A/A-теста. Если вы внесете эти значения в любой калькулятор, он сообщит вам, что результат не является статистически значимым. На самом деле, этот результат является всего-навсего большим куском бессмысленной информации.
Множественное сравнение
Еще одна очень опасная ошибка, которую допускает большинство маркетологов, — проведение сразу нескольких A/B-тестов одновременно. Выделим несколько разновидностей такого тестирования:
-
Проведение одновременно нескольких A/B-тестов, которые влияют на одну и ту же метрику и затрагивают одни и те же сегменты пользователей.
-
Мультивариативное тестирование («какой из 5 дизайнов покажет лучшую конверсию?»).
-
Сегментирование постфактум. Когда вы сначала провели тест, а потом смотрите его результаты на разных сегментах, пока не найдете хотя бы один, который даст положительный результат.
Ответ на вопрос, почему такое проведение тестов является плохой идеей, лежит в простой арифметике и в понимании такого термина как коррекция на множественное тестирование.
Каждый тест имеет шанс 5% (если мы выбрали p-value = 0,05) показать победителя там, где его в действительности нет. Это довольно маленькая вероятность, которая является удовлетворительной в большинстве случаев. Однако при проведении n таких тестов вероятность того, что хотя бы один из них будет неверным, равна 1 — (1 — 0.05)n, что велико уже даже при небольших n (например, при n = 5 она равна примерно 23%!).
Таким образом, проводя много тестов, вы несомненно найдете победителя, однако ваша «победа» будет всего лишь иллюзией.
Регрессия
С большим сомнением относитесь к тестам, которые были крайне успешными, но при повторном проведении не подтвердили свои результаты. Вы можете подумать, что просто со временем результат пропал. Но настоящая правда заключается в том, что скорее всего этого результата вовсе не было, и в первый раз вы просто получили false-positive результат.
Это хорошо известный феномен, который в статистике называется регрессией. Этот термин общеизвестен среди статистиков, но многие специалисты по A/B тестированию едва ли о нем слышали.
Возьмем простой пример. Допустим, есть класс студентов, которые выполняют тест из 100 пунктов, где возможны только два варианта ответа — «да» и «нет». Предположим, что все студенты выбирают ответы абсолютно случайным образом. В итоге каждый студент получит за тест случайный балл — от 0 до 100 со средним баллом по классу примерно 50.
Теперь возьмем 10% из тех студентов, кто набрал максимальный балл, и назовем их «отличниками». После чего дадим им тот же самый тест, в котором они опять же ответят на вопросы случайным образом. Результат при второй попытке у них будет ниже, чем в первый раз. Это связано с тем, что абсолютно не важно, какую оценку они получили в первый раз. Они все равно наберут в среднем 50 баллов. Отсюда появится ложное впечатление, что «отличники» резко стали менее умными. Однако, правда заключается в том, что они никогда не были умнее, чем остальные.
В A/B-тестировании происходит абсолютно то же самое. Если ваш первый тест был false-positive, то все последующие тесты конечно же покажут уменьшение «разницы», которой на самом деле не было. И причиной этому будет регрессия к среднему значению.
Поэтому, если ваш повторный тест через какое-то время не показал прироста к конверсии, задайте себе вопрос: а был ли мой первоначальный тест проведен правильно? Если вы хотите быть уверены в результатах своего тестирования — всегда проводите контрольное тестирование через некоторое время, чтобы убедиться в том, что результаты первого теста были верными.
10 советов правильного A/B-тестирования
На этом мы закончим изучение скучной «мат. части» и перейдем к выводам, которые следуют из всего описанного выше. Мы составили список из 10 основных советов, которые помогут вам правильно проводить тесты и быть уверенными в их результатах.
Определите минимальный размер выборки до начала теста
Всегда заранее определяйте количество посетителей сайта, необходимых в каждую ветку теста! Не стоит просто запускать тест в надежде, что быть может через неделю результат будет статистически значимым и вы сможете принять решение в пользу той или иной альтернативы. Даже если он и будет статистически значимым — это ни о чем не говорит, если выборка не достигла определенного заранее размера.
Можно встретить много статей, где пишут «вам нужно минимум 1000 конверсий в каждую ветку для проведения теста» или «примерно 3000 наблюдений на каждую вариацию в большинстве случае достаточно». Не существует никаких магических цифр! Все зависит исключительно от цели вашего теста, базовой конверсии вашего сайта и величины видимого эффекта.
Для определения размера выборки в каждую ветку теста вы можете воспользоваться нашим калькулятором: http://tools.driveback.ru/sample-size.html
Игнорируйте результаты A/B-теста, пока он не завершен
Заведите привычку даже не заглядывать в результаты теста до его окончания. Даже если в первой ветке вы видите 100 конверсий из 1000 посетителей, а во второй всего лишь 50 из 1000 — игнорируйте этот результат. Он совершенно ни о чем не говорит и еще много раз может измениться в любую сторону до окончания теста.
Проверяйте статистическую значимость результата лишь после проведения теста
Статистическую значимость результата необходимо проверять только после окончания теста. Для этого существует множество инструментов, таких как калькулятор у нас на сайте: http://tools.driveback.ru/significance.html
Если результат не является статистически значимым — не стоит пытаться подобрать сегмент, где он является значимым, или пробовать менять другие параметры. У вас остается только два выбора:
-
Смириться с тем, что величину видимого эффекта, которую вы определили до начала теста, увидеть невозможно.
-
Продлить тест еще на несколько недель.
Тестируйте все дни недели и все бизнес-циклы
Ваш тест должен проходить в течение одного, а лучше двух полных бизнес-циклов и должен включать:
-
Все дни недели.
-
Все источники трафика (если только вы не проводите тест для определенного источника трафика).
-
Весь цикл публикаций и рассылок, которые вы проводите регулярно.
-
Достаточное количество времени для посетителей сайта, которые не принимают решение сразу (а думают над покупкой в течение
10-20 дней). -
Любые другие внешние факторы, которые могут влиять на конверсию (к примеру день зарплаты, день аванса, праздники и т.д.)
Используйте сегментирование
Заранее определите сегмент пользователей, для которых проводится тест.
Допустим, вы хотите протестировать, влияет ли специальное предложение на карточке определенного товара на вероятность его покупки.
Альтернатива A: вы отображаете скидку 10% на карточке товара «Х».
Альтернатива B: вы не отображаете никаких скидок на карточке товара «Х».
Не стоит проводить тест по всей аудитории сайта. Его стоит проводить среди тех пользователей, кто теоретически мог увидеть скидку (был на карточке товара «Х»). Все остальные пользователи для нас просто не представляют интереса и лишь будут уменьшать величину видимого эффекта.
Забудьте про A/B-тесты, если у вас нет трафика!
Если вы делаете
Как бы вы ни любили A/B-тестирование, это явно не то, что вы должны использовать для оптимизации конверсии при маленьком трафике. Даже если вариант B значительно лучше, у вас могут уйти месяцы (а иногда и годы!), чтобы достигнуть статистической значимости результата.
Таким образом, если вы будете проводить тест 5 месяцев — вы просто-напросто выбросите на воздух кучу денег. Вместо этого нужно иди на более значительные и радикальные изменения — просто реализовать вариант B без какого-либо тестирования. Никаких A/B-тестов, просто переключайтесь на B и наблюдайте за своим счетом в банке!
Дело в том, что если вы собираетесь вносить какие-то изменения на сайт без трафика, то вы ожидаете большого подъема в прибыли или генерации лидов: 50% или 100%. Вы легко заметите этот подъем на вашем счете в банке даже без каких-либо тестов уже в первую неделю (либо это может быть резкое увеличение количества собранных е-мэйлов или полученных звонков).
Время — деньги! Не тратьте зря время на ожидание результатов, которые займут многие месяцы.
Проводите тесты только на основе гипотез
Гипотеза — недоказанное утверждение, предположение или догадка. Как правило, гипотеза высказывается на основе ряда подтверждающих её наблюдений (примеров), и поэтому выглядит правдоподобно. Гипотезу впоследствии или доказывают, превращая её в установленный факт, или же опровергают, переводя в разряд ложных утверждений.
Начинать тестирование, не привязанное к какой-либо гипотезе — это то же самое, что садиться за руль и просто ехать, не понимая, куда вы едете и почему. Возможно, в итоге вы куда-то приедете, вот только какой опыт вы от этого получите и к каким выводам придете?
Вы можете потратить кучу времени и ресурсов, меняя цвета кнопок, шрифты, размер текста. Однако, такое тестирование будет бессмысленно, если в основании не лежит рациональная гипотеза, подкрепленная весомыми аргументами.
«Я думаю, что на синюю кнопку будут нажимать чаще, чем на зеленую» — адекватной гипотезой не является!
Поэтому мы настоятельно не советуем проводить бессмысленные A/B-тесты, не подкрепленные никакими данными — они никак не повлияют на вашу прибыль. Даже если каким-то случайным образом вы и получите положительный результат — какой урок вы из него вынесете? Никакого. Ведь куда важнее то, что вы узнаете о своей аудитории. Это поможет вам изучать поведение посетителей вашего сайта и в будущем планировать более успешные тесты.
Не проводите несколько тестов одновременно
Проведение одновременно нескольких тестов — верный путь получить false-positive, о чем мы подробно описали в разделе про множественное сравнение.
Допустим, вы тестируете, как на покупку вещи «Х» отразится баннер на главной странице. При этом вы также тестируете, как на все покупки отразится скидка 10% за подписку на рассылку. В итоге, вы случайным образом разделите всех ваших посетителей на следующие сегменты:
Таблица 1: Проведение одновременно двух A/B-тестов.
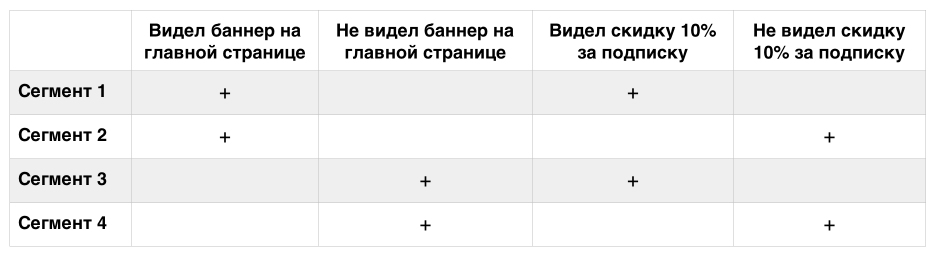
Создав 3 одновременных A/B теста — вы получите уже 8 сегментов. Даже если вы все-таки сумеете правильно сгруппировать сегменты для определения результатов каждого теста в отдельности — следует учесть поправку на множественное тестирование. Если в каждом отдельном тесте уровень статистической значимости был 95%, то при проведении 2 тестов (4 сегмента) одновременно — уровень статистической значимости станет всего 81,4% для каждого теста. Это значит, что в 18,6% случаев вы будете видеть результат там, где его в действительности нет. Как мы уже говорили ранее, минимальный уровень значимости для правильного проведения A/B-тестов должен быть не ниже 95%.
Поэтому никогда не проводите более одного A/B-теста, если вы понимаете, что дополнительные тесты затронут тот же сегмент пользователей. В самом же A/B-тесте никогда не используйте более 2 вариаций, забудьте про мультивариативное тестирование.
Не ожидайте большого увеличения конверсии
Мы часто встречаем клиентов, которые видят увеличение конверсии на 2% и говорят что-то вроде «Всего 2%? Это слишком мало! Даже не хочется заморачиваться с реализацией этого изменения».
Но вот в чем правда. Если ваш сайт хорош, вам вряд ли стоит ожидать больших скачков в конверсии. Если кто-то показал вам результаты A/B-теста, согласно которому вашу конверсию увеличили на
- Ваш сайт — реальное г**но.
- Вас обманули (или неправильно провели тест).
Большинство выигрышных тестов дают небольшое увеличение конверсии — 1%, 2%, 5%. Для некоторых крупных интернет-магазинов увеличение конверсии даже на 1% может дать в результате увеличения выручки на миллионы рублей. Тут уже все зависит от абсолютных цифр. Но посмотрите на все это в перспективе 12 месяцев.
Один тест — это один тест. Но вы собираетесь делать множество тестов. Даже если увеличивать конверсию на 1% каждый месяц — это уже 12% в течение года! 12% к выручке — значительный результат.
Стремитесь к маленьким победам. Ведь в конце концов каждая из них внесет вклад в общее увеличение прибыли.
Всегда проводите повторный тест спустя некоторое время
Тут правило простое. Ваш тест показал впечатляющие результаты, но вы не до конца уверены в природе столь хороших результатов? Мало того, после реализации изменений на сайте вы не видите существенного изменения в прибыли?
Обязательно проведите повторный тест спустя несколько месяцев. Может оказаться, что в прошлый раз вы всего лишь получили false-positive.
——
Используйте приведенные выше советы при проведении следующего A/B-теста. Даже если вы и не сможете добиться увеличения конверсии — вы хотя бы не уменьшите ее, полагаясь на ошибочные и иллюзорные результаты неправильно проведенного теста.
На иллюстрации к статье изображена оптическая иллюзия восприятия цвета.
Оригинал: http://blog.driveback.ru/2015/04/why-a-b-tests-decrease-conversion/
Чтобы не пропустить новые материалы на CMS Magazine,
подпишитесь на наши каналы в MAX или Телеграм
подпишитесь на наши каналы в MAX или Телеграм
 Канал в MAX
Канал в MAX Канал в TG
Канал в TGИщете исполнителя для реализации проекта?
Проведите конкурс среди участников CMS Magazine
Узнайте цены и сроки уже завтра. Это бесплатно и займет ≈5 минут.
похожие статьи
Вакансии
на workspace.ruB2B-лидогенератор/ менеджер по привлечению продавцов в маркетплейс
ООО СОФТРЕСУРСУдаленно30,000 — 150,000 ₽
SEO-специалист
1PS.RUУдаленно80,000 — 90,000 ₽
Куратор образовательного проекта
АннаУдаленноот 70,000 ₽
DevOps
RadMateУдаленноот 170,000 ₽
Менеджер ВК
Смотреть всеАннаУдаленноот 75,000 ₽
Наверх
Агентства
Проекты компании Proactivity Group




© 2006-2026 CMS Magazine
Электронное СМИ. Эл № ФС 77-32705
18+