Вот притащили вам с охоты мамонта: выше вас ростом, упитанный и на вид пока несъедобный. Что делать?! Декомпозировать, конечно: лапы отдельно, шкуру отдельно. Но с чего начать? И когда хоть примерно будет готов ужин?
Если вам достался жирненький проект, вопросы примерно такие же — какой круг задач предстоит, и как их предварительно оценить. Декомпозиция — крутой способ разложить всё по полочкам и прикинуть объём работ, заложить резервы на трудные блоки и докопаться до неприятных задач со звездочкой. Как это сделать, мы уже рассказывали в одном из обучающих видео. А для любителей вдумчивого чтения мы преобразовали его в крутую статью.
Больше не нужно искать и обзванивать каждое диджитал-агентство
Создайте конкурс на workspace.ru – получите предложения от участников CMS Magazine по цене и срокам. Это бесплатно и займет 5 минут. В каталоге 15 617 диджитал-агентств, готовых вам помочь – выберите и сэкономьте до 30%.
Создать конкурс →
Создайте конкурс на workspace.ru – получите предложения от участников CMS Magazine по цене и срокам. Это бесплатно и займет 5 минут. В каталоге 15 617 диджитал-агентств, готовых вам помочь – выберите и сэкономьте до 30%.
Создать конкурс →
Уровни декомпозиции
Казалось бы, проще простого: режем проект на большие части, эти части — ещё на части, а те части — снова на части. Но действительно так ли всё просто?!
Уровни декомпозиции
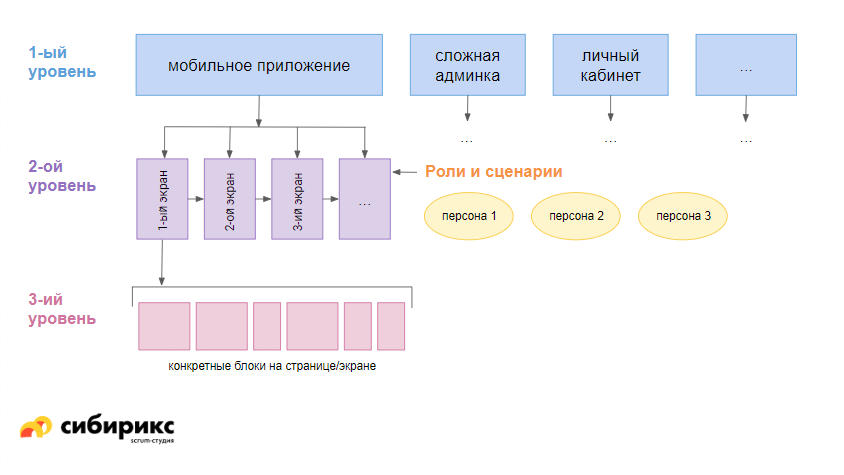
Уровень. Крупные блоки или компоненты
Это может быть блок с е-коммерсом, личный кабинет, мобильное приложение, супер-навороченная админка. В общем, любые блоки работ, которые могут быть как-то между собой связаны, но которые можно делать изолированно друг от друга.
Уровень. Страницы сайта или экраны мобильного приложения
В случае с блоком «мобильное приложение», как на схеме выше, разбиваем его на экраны. Но как узнать, что вы учли все-все-все возможные экраны? Для проверки полноты берите в расчёт сценарии использования — это даст понимание, какие задачи юзеры будут решать в приложении (или на сайте) и каким примерно образом они это будут делать.
Пример
Для e-commerce основной сценарий — продавать, а путь пользователя в нём выглядит так: каталог → список товаров → карточка товара и так далее.
Есть соблазн написать в смете только сценарий использования и его оценку (скажем, сценарий покупки товара или сценарий заказа такси) — ну, ведь понятно же, что там внутри. Нет, непонятно, и есть большой риск потерять множество шагов, поскольку такие сценарии большие, и их крайне сложно адекватно оценить целиком.
Когда сценарий раскладывается на экраны, шансов ошибиться становится меньше. Но помните, что каждый сценарий стоит проверять на связанность — достаточно ли вам вот этих экранов, чтобы этот сценарий сбылся?
Пример
У нас есть маркетплейс — магазин, куда другие производители могут загружать свои товары. Сценарии, лежащие на поверхности: загрузка своих товаров (загрузка и описание, разделы каталоге и вот это вот всё), покупка товара (шаги покупателя на пути к цели), обработка заказа (как будут распределяться деньги, как будет получать свою долю маркетплейс и так далее). Если всё это не расписать подробно, можно запросто упустить кучу нюансов.
Будет ещё легче, если вы выделите ключевые роли на проекте (пользователь, администратор интернет-магазина и т.д.), у каждой из которых есть свой сценарий, а у каждого сценария — свой набор экранов. И тогда проверить полноту экранов ещё проще — достаточно посмотреть, связан и выполняется ли сценарий конкретной роли по ним.
Уровень. Содержание экранов
В общем случае у вас на экранах могут быть какие-то вкладки либо какие-то блоки — грубо, вложенные экраны. Например, страница корзины/оформления заказа — здесь всегда есть блок товаров со своим сценарием (добавить-убавить-очистить), а еще блоки доставки, оплаты, авторизации, бонусной системы и так далее. Бывают ситуации, когда эти блоки также разбивают на экраны по шагам. Зависит от решения, принятого по итогам аналитики — бывает, что удобнее их всё-таки «слить» воедино.
Задача менеджера, когда он добрался до такого экрана, — посмотреть, из чего тот состоит. Бывает, экран легко разбить на блоки, бывает — сложно. Яркий пример сложной разбивки — калькуляторы: по ним чаще всего неочевидно, что происходит и как процесс расчёта делить на шаги.
Когда вы добираетесь до третьего уровня, нужно быть супер-внимательными, потому что на странице могут появляться самые разные вещи. И важно понимать, откуда они там вообще берутся — от этого будут сильно зависеть ваши оценки.
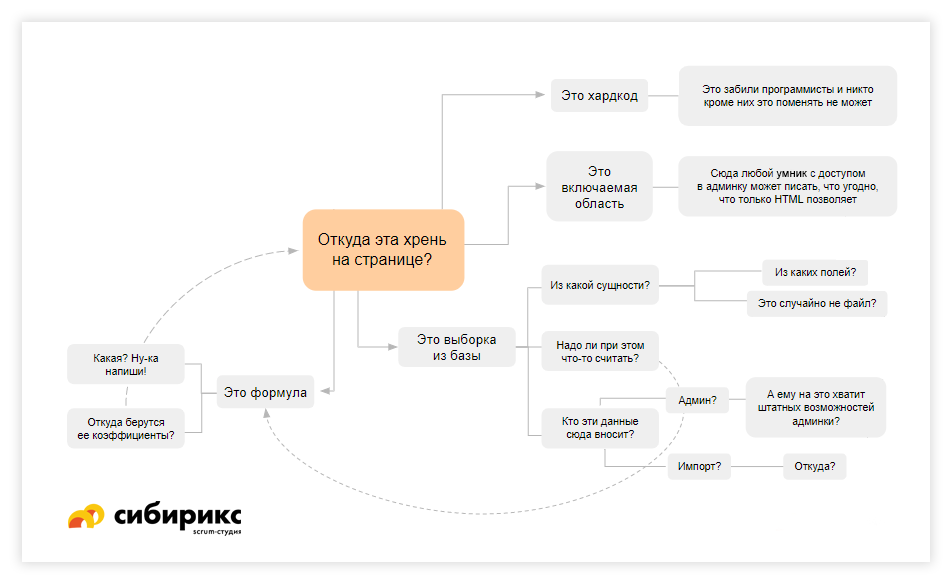
Откуда эта хрень на странице?!
Итак, вы добрались до какого-то блока или страницы. Самое время задать себе вопрос «Откуда это на странице?!». Но проджекты, аналитики и аккаунт-менеджеры (и даже заказчики) вот тут часто-часто ленятся — «подумаем об этом потом».
Например, аналитик сказал: «это мы как-нибудь на коде решим», а потом на планинге сидят 4 умных человека, смотрят друг на друга и спрашивают: «кто это придумал, что это за маразм?!». Такая ситуация — явный признак, что где-то недоработали раньше. Бывает, конечно, что принятие какого-то решения действительно откладывается, но это должно быть осознанно и где-то зафиксировано.
Чем меньше вы понимаете в момент «Откуда это на странице!?», тем больше у вас должен быть зазор в смете. И когда к вам приходит клиент и говорит «а почему тут такой большой зазор?!», у вас должен быть готовый ответ — потому что вы не понимаете, как работает то, то и это (лучше — фиксированный перечень конкретных вопросов), и что эти вопросы вы будете выяснять вместе с ним позже.
Итак, какими могут быть варианты, откуда берутся данные на странице?
Вариант. Хардкод
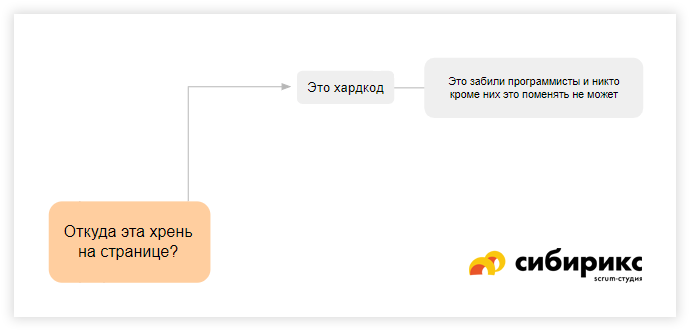
Самый простой в реализации вариант ответа на наш вопрос — хардкод. Это значит, что программисты сели, прямо в коде зафигачили какую-то штуку, и теперь поменять ее могут только они. Самые частые блоки, с которыми так делают — логотипы компаний, иногда ссылки на соцсети, время от времени такое делают с меню (всё реже), телефонами (плохо!), декоративными элементами на верстке. Всё это — более-менее разумные моменты. Неразумно, это когда в код зашиваются, например, ВСЕ страницы или SEO-тексты блоками.
Вариант. Включаемая область
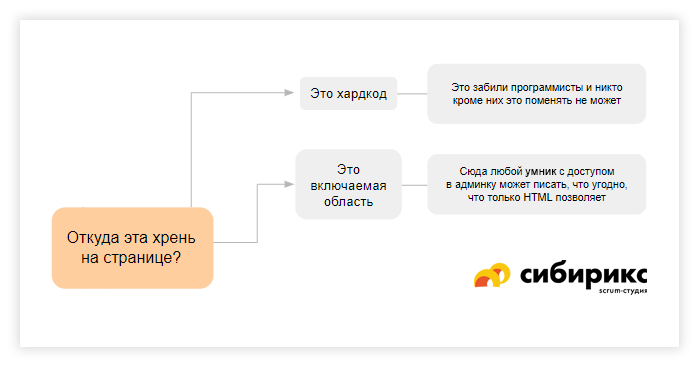
У включаемых областей есть специфика: во-первых, их можно случайно удалить. Во-вторых, если в них указываются даты мероприятий или цены на товары, это чревато путаницей, поскольку у этих областей нет связанности: если поменять дату или цену в одном месте, в другом она останется той же. Клиенты зачастую сразу говорят, что такого им не нужно — а значит, придётся продумывать, как менять цены, даты и прочие изменяемые поля автоматически и повсеместно.
Вариант. Из админки (из базы данных)
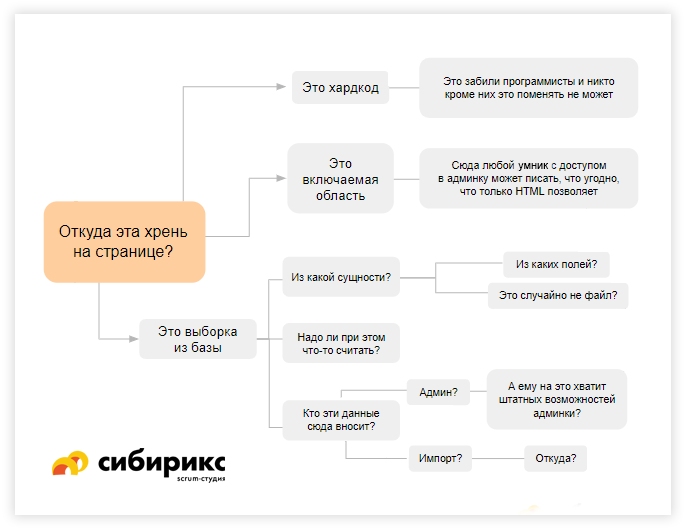
Итак, мы знаем, что какие-то данные выбираются из базы данных. Тогда нам нужно понимать, из какой сущности и из какого поля. Примеры сущностей в интернет-магазине: «товар», «раздел», «пользователь», «заказ» — то есть то, что состоит из каких-то полей. Поля — например, «цена».
Но достаточно ли нам будет понимать, из какой сущности и из какого поля выводятся данные? Не совсем. Когда выбираете какую-то информацию из базы, она может выводиться не в том виде, как она там хранится, а в несколько модифицированном.
Например, это формула
Когда информация хранится в базе, но ее нужно как-то определенным образом модифицировать, появляется понятие «формула». Одна из самых опасных вещей, которую менеджеры часто пропускают.
Когда вам аналитик говорит «ну там это как-то считается» — навострите ушки, впереди точно будет затык. Математики не понимают программистов и считают что, их формулу достаточно переписать и следом «просто» запрограммировать — делов-то. Но когда клиента начинаешь спрашивать о формуле, часто слышишь что-то вроде «ой, она у нас там в excel», или " механика пока непонятна«, или вообще «ну скопируйте вон с того сайта».
Видите формулу — копайте глубже. У неё внутри есть коэффициенты — а откуда берутся эти коэффициенты? Добро пожаловать в новый виток расследования «Откуда эта хрень на странице!?».
Вот из-за этого о формулах никто не любит думать:)
Например, это файл
В зависимости от используемой технологии бывает, что часть данных хранится в файлах. Может показаться, что это какая-то сущность или поле сущности, но это всё-таки ФАЙЛ.
Очень часто файлы в самой базе данных не хранятся, чтобы не «раздувать» её. Из-за этого работа с ними организована иначе. В случае банального каталога товаров файлом может быть фотография у пользователя (userpic), описания, спецификации в pdf и всё такое прочее. Такие файлы находятся не совсем в базе, но при оценке важно понимать, что они есть.
Как данные попадают в базу данных?
Обычно администратор или контент-менеджер садится и забивает данные ручками. Тогда здесь должен возникать вопрос, а хватит ли ему стандартных компонентов админки для этого. Для этого ПМ должен быть очень хорошо знаком с возможностями стандартной административной панели. А ещё с ними должен быть знаком аналитик и тестировщик (про кодера, понятно, молчим). В Сибирикс все QA-специалисты проходят базовый курс контент-менеджера, чтобы понимать, на что способна админка. Ну а про то, что QA-спецы у нас обычно вырастают в проджект-менеджеров, мы уже как-то писали.
Пример
У вас на дизайне есть слайдер, где расставлены точки, по клику на которые открывается всплывашка, в которой есть фотография, описание и ссылка на куда-нибудь. Вопрос: как расставлять эти точки? Как вариант — координаты X и Y, но вряд ли контентщик будет счастлив от такого функционала. А значит, придётся что-то придумывать. И значит, в смету нужно это заложить.
Второй момент, который проджекты часто упускают, — права доступа и хватит ли их. А значит, это тоже нужно иметь ввиду и сразу перечислить потенциальные роли.
Вариант. Интеграция со сторонним ресурсом
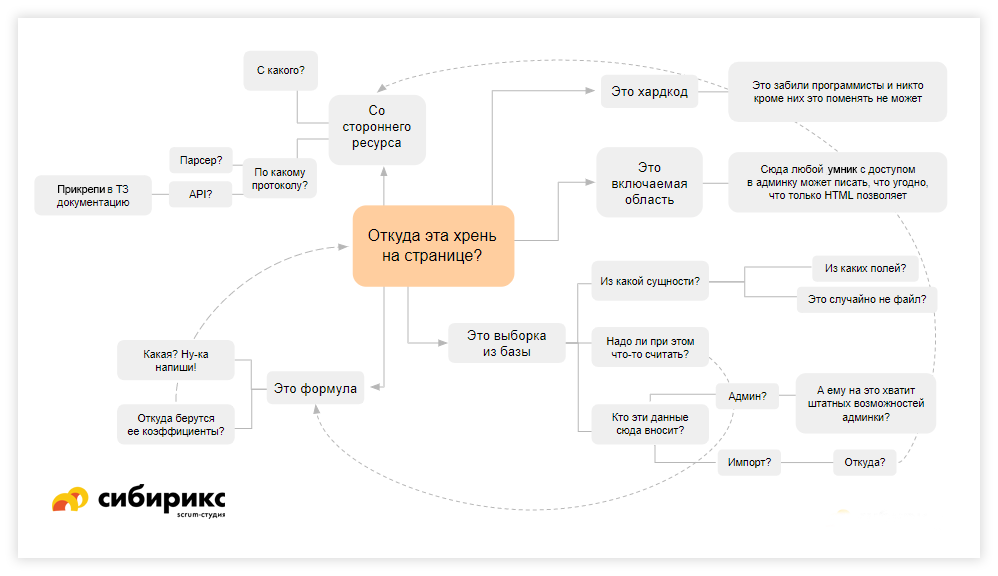
Один из источников данных в базе — пользовательский контент. И здесь важно понимать, как он попадает в базу. На этом этапе часто теряется один из крупных сценариев: например, как пользователь вносит отзывы. У отзывов часто бывает рейтинг — штука с виду простая, но внутри она может быть довольно сложно организована. У чего больше рейтинг? Там, где поставили одну оценку в 10 баллов, или где 1000 оценок, но разных? Среднеарифметическое тут работает плохо. Но хитрые алгоритмы есть — привет, ещё один резерв в смете.
Если данные берутся всё-таки с внешнего источника, то без интеграции никак. Вариантов интеграции может быть несколько:
Парсинг
Парсинг — не самая приятная тема. Когда вам говорят «сходите за этими данными на сторонний ресурс и аккуратненько всё своруйте», заканчивается это чаще всего плохо. А когда еще этих ресурсов
Другая проблема — админы сайтов, с которым парсятся данные, не слишком счастливы, что эти данные кто-то «ворует», и будут всячески защищаться. А это приводит к «падению» парсинга и попаданию в черные списки. Вы попытаетесь с этим бороться добавлением каких-нибудь платных proxy — короче, целый квест. Есть особые сервисы для организации парсинга — например, Mozenda, Automation Anywhere, Beautiful Soup, WebHarvy или Content Grabber (полный список из 30 сервисов ищите тут).
API
Здесь имеется ввиду, что есть какой-то интеграционный протокол, либо файловый протокол, либо XML, либо шина данных (сервер очередей вроде RabbitMQ, ZerroMQ или Apache Kafka) — подробнее о разнице штатной интеграции и по API наш техдир рассказывает тут. С чем именно интегрировать и по какому протоколу, на этапе предварительной оценки не столь важно — важнее, есть ли для этого документация. А у неё обычно бывает два состояния:
-
она есть — это когда можно в любой момент зайти и посмотреть на неё глазами, а внутри реально описаны методы;
-
она «почти есть» — как правило, это говорит о том, что внутри ерунда, а вы будете подопытными обезьянками, на которых будут всё эту сырую штуку тестировать.
Хуже всего бывает, когда говорят «ну вы, программисты, между собой договоритесь и разберитесь сами как-нибудь». Если протокол не формализован и взаимной ответственности нет, критический путь проекта будет пролегать через интеграцию, и на ней он завалится. Или по крайней мере, здесь потратится куча времени на согласование с программистом заказчика его протокола и отладку.
Соответственно, если на проекте планируется интеграция с внешним сервисом, на неё нужно закладывать большие резервы. Лайфхак, если нужно интегрироваться, а протокола пока нет — делать MOCK-объекты. Это специальные заглушки для интеграционного протокола, которые можно быстро сделать. А как только будет реальный протокол — просто заменить их (но обязательно с перепроверкой).
Как все это «подружить»
Начинаем с крупных компонентов: первый, второй третий — можно расписать подробно. Следом важно примерно понять, какие есть пользователи (роли) и какие у них сценарии. Сами сценарии в смету лучше не прописывать. Дальше — идём по страницам. После — работаем с отдельными блоками, используя уже известную схему «Откуда эта хрень на странице?!».
Как только вы слышите слово «калькулятор» или «считается», напрягайтесь :) Когда есть интеграция со сторонним сервисом — тоже. В остальном — ничего страшного, и всё довольно прозрачно :)
Когда это может не сработать
Если на проекте есть какая-то дремучая математика, и вы живете в мире, полном злых неожиданностей, то декомпозиция по экранам будет давать сбой. В общем случае она довольно хорошо показывает, что и как происходит на типовых проектах.
Успехов в декомпозиции и почаще заглядывайте к нам на YouTube-канал за новыми полезными видео для проджектов (и не только)!
Чтобы не пропустить новые материалы на CMS Magazine,
подпишитесь на наши каналы в MAX или Телеграм
подпишитесь на наши каналы в MAX или Телеграм
 Канал в MAX
Канал в MAX Канал в TG
Канал в TGИщете исполнителя для реализации проекта?
Проведите конкурс среди участников CMS Magazine
Узнайте цены и сроки уже завтра. Это бесплатно и займет ≈5 минут.
похожие статьи
Вакансии
на workspace.ruСмм-менеджер / помощник маркетолога
GetOfferУдаленно30,000 — 50,000 ₽
SEO-специалист
QLANУдаленно
Senior UX Researcher
F`ARTУдаленно
Специалист по маркетингу
ясалтаяУдаленно30,000 — 60,000 ₽
Стажировка для SMM-специалистов
Смотреть все«Лайка»Удаленно
Наверх
Агентства
Проекты компании Proactivity Group




© 2006-2026 CMS Magazine
Электронное СМИ. Эл № ФС 77-32705
18+
CEO & Founder
С файлами ещё бывает история, что их нужно хранить на отдельных серверах, или в облаках S3, закачивая по специальному протоколу, но это уже нюансы масштабирования. На старте проекта, окупаемость которого непонятна, городить тут огород я не вижу смысла. Исключение — тяжелый видео-контент. Его лучше сразу писать в видеохостинги.