Я расскажу о том, для чего нужен seo аудит сайта, какие задачи решает, какие проблемы призван исправить и, собственно, самое важное — как все это решить и сделать самостоятельно!
Аудит сайта: для чего нужен и какие задачи решает?
Изначально я планировал написать чисто о техническом аудите сайтов, а потом вспомнил, какие трудности я каждый раз испытываю, договариваясь с очередным заказчиком о проведении аудита. Что будет входить в аудит, какие рекомендации и касательно чего? Если даже мне самому сложно определиться в этом вопросе, даже не представляю, чего будет стоить это вам.
Для кого-то технический аудит — это результат работы какого-нибудь автоматического сервиса для проведения экспресс аудита, где в результате мы узнаем, какой тИЦ у сайта, сколько страниц проиндексировано в Яндексе и Гугле, в каких каталогах сайт находится, сколько на него обратных ссылок, увидим тошноту главной страницы и ее title. И что? Зачем нам эта информация? Для чего нам знать, сколько страниц в индексе, если понятия не имеем, что это за страницы? Зачем нам количество обратных ссылок без понимания природы их происхождения? Зачем нам знать тошноту текста главной страницы, если ее title просто «Главная»?
По моему мнению, именно на такие вопросы и должен ответить аудит. Вопросы, ответы на которые нельзя автоматизировать, ответы, которые требуют углубленного изучения сайта и его бэкграунда.
Не менее сложно определить границы, где заканчивается техническая часть, а где начинается юзабилити или маркетинговая составляющая. Отсутствие кнопки «заказать в 1 клик» на карточке товара — это техническая недоработка или проблема с юзабилити? А сложности при оформлении заказа в интернет-магазине: слишком большая форма для заполнения или ссылка из письма о подтверждении заказа, ведущая на любую страницу, кроме сообщения об успешном оформлении...
Я могу перечислять бесконечно! Сколько там у меня за плечами аудитов за мою практику... 200... 300, может, 500? И все они были комплексные, потому что нельзя просто так взять и пройти мимо очевидной ошибки, следуя формальностям, мол, это не относится к технической части.
Итак, примерное понимание, для чего нужен технический аудит у вас уже должно быть. Постараюсь формализовать список задач, которые должен решать аудит:
-
Технические моменты: 404 ошибки и битые ссылки; дубликаты страниц и повторы title; настройка метатегов; использование заголовков на страницах; чистота и корректность кода страниц; соответствие базовым требованиям поисковых систем;
-
Индексация сайта: какие страницы на сайте доступны для индексации, а какие по факту в индексе; нет ли проблем с метатегами, отвечающими за индексацию;
-
Скорость загрузки сайта и отдельных страниц, выявление причин медленной работы сайта;
-
Работоспособность сайта и его составляющих;
-
Функционал сайта, соответствие его требованиям и алгоритмам поисковых систем для определённых тематик и типов запросов.
Как видите, фронт работ колоссальный. Разобраться со всем этим, если вы не специалист, будет сложно, а для кого-то и невозможно.
А если говорить о стоимости услуг, то первые 3 пункта будут стоить 20 000р., т.к. максимально поддаются автоматизации, а все время работы занимает перечисление, описание и объяснение где, что и как надо сделать. Все пять пунктов, скажем, могут стоить уже 50 000р. И может быть, эти три дополнительных пункта выльются всего в
1-2 листа рекомендаций, но за ними стоит серьёзная работа. Сколько по-вашему может стоить сообщение о том, что форма заявки на вашем сайте не работает? Или кнопка продолжить в корзине постоянно перебрасывает пользователя на первый шаг и не продолжает оформление заказа? И вопрос тут в другом — а какие убытки вы понесете! Бесценно. И ситуации эти реальны, они из моей практики. (Возвращаясь к ценам, скажу, что это мои расценки, а у каких-нибудь московских seo-компаний все будет в3-5 раз дороже, а у средненького фрилансера в 2 раза дешевле. Решать вам.)
Инструменты, необходимые для проведения полноценного аудита
Панель вебмастера Яндекса
Как только вы создаете сайт, либо берете клиентский сайт на продвижение, первое, что надо сделать — получить (создать) доступ в панель Яндекс.Вебмастер и Яндекс.Метрику. Это не требует никаких специальных знаний. Потом зайдите в раздел уведомлений в панели Вебмастера.
Нет времени объяснять, просто смотрите:
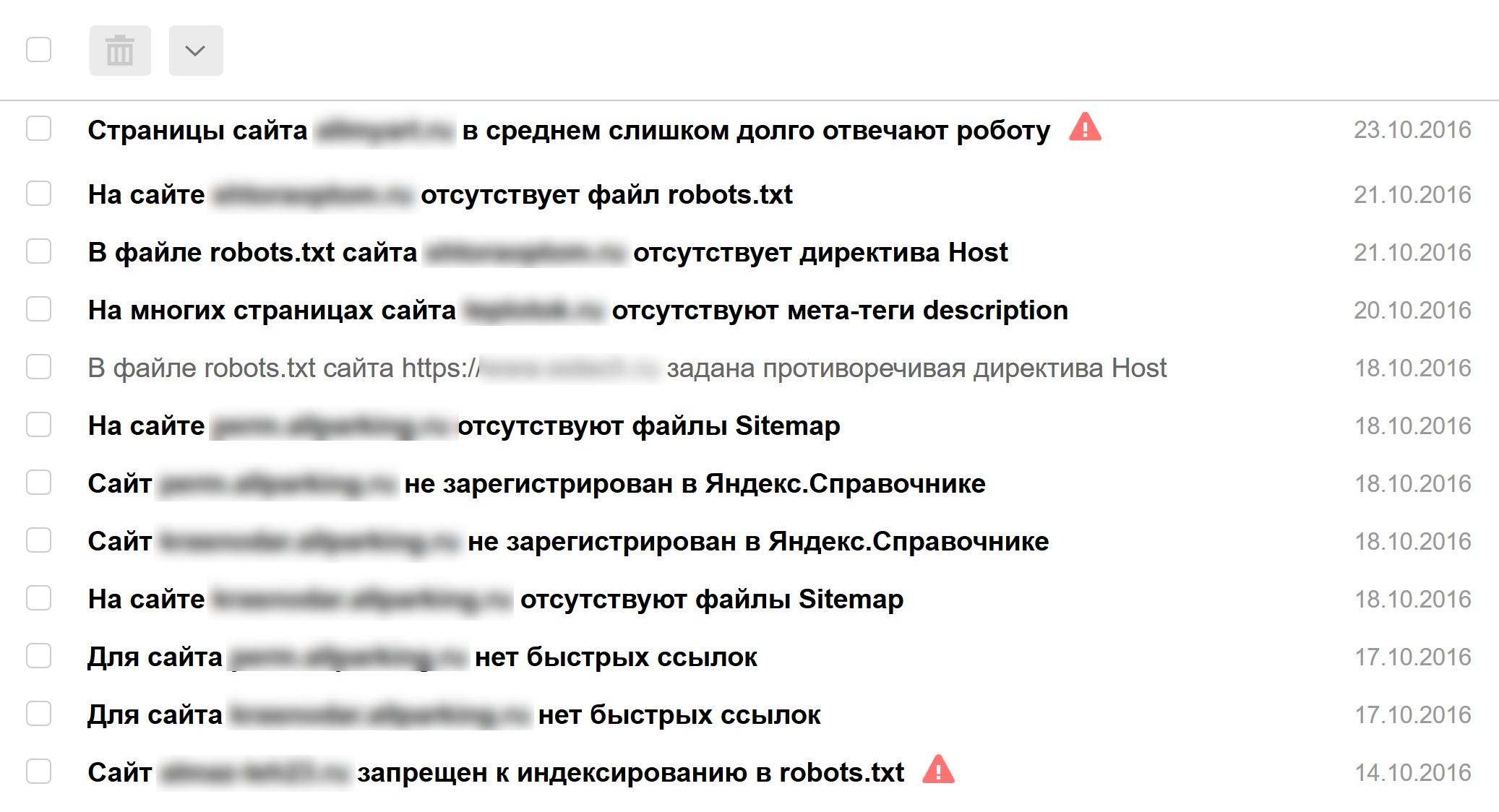
Важно ли это? Очень важно!
Панель вебмастера Яндекса обрела новую жизнь, когда ее обновили до версии 2.0. В разделе диагностики сообщают о критических и возможных проблемах и выдают рекомендации. В разделе безопасность сообщают о вирусах и вредоносном коде, в нарушениях — о наложенных фильтрах (например, если вы перестарались со ссылками и получили Минусинск).
Следующий важный раздел — Индексирование — где можно посмотреть, какие страницы проиндексированы, какие участвуют в поиске, а какие отдают ошибки.

Отдельное спасибо за то, что все данные из панели можно выгружать в виде архива, где, по их словам, содержится исчерпывающая информация. Жалко, что с этими данными нельзя взаимодействовать, например, отметить проблемы с несуществующими или запрещенными к индексации страницами, как решенные, чтобы пропали из статистики, как это сделано в Google Search Console. Но с другой стороны, забот меньше, не так ли? :)
Что еще стоит обязательно сделать в панели вебмастера Яндекса:
-
Добавить файлы sitemap.xml;
-
В разделе Переезд сайта указать основное зеркало;
-
В разделе «Региональность» указать регион, либо убедиться, что указан нужный регион;
-
Выбрать регистр сайта. Просто для красоты, либо в надежде, что это немного увеличит CTR на выдаче;
-
В Быстрых ссылках провести ревизию, чтобы показывались только самые важные ссылки в нужном порядке. Об изменениях в быстрых ссылках приходят сообщения в «Уведомления»;
-
Все остальное уже по ситуации и в зависимости от требований.
Обычно я договариваюсь с заказчиком, что все настройки в панели произвожу сам, потому что описывать, что и как сделать, намного дольше, чем все настроить самостоятельно.
Google Search Console (Панель для веб-мастеров)
Добавить сайт в панель Гугла — это такое же необходимое действие. Здесь есть раздел с важными сообщениями, где хранятся рекомендации для сайтов и сообщения об ошибках:

Сайт плохо индексируется? 404 ошибки? Вам сообщат!
Немного раздражает, что для указания главного зеркала сайта (Шестеренка в правом верхнем углу — Настройки сайта — Основной домен), необходимо все зеркала добавить и подтвердить в панели и только потом для зеркал указывать основной сайт. Потом все эти зеркала для всех сайтов будут в общем списке болтаться. Бесит!
Следующий важный раздел: Вид в поиске — Оптимизация HTML. Стоит обратить особое внимание на пункт «Повторяющиеся заголовки (теги title)». Дубликаты title говорят о серьёзны недочетах. Основных причин несколько: у вас некорректно формируются title, у вас есть дубликаты страниц, не закрыты от индексации «лишние» страницы.
Раздел «Меры, принятые вручную» — здесь по аналогии с Яндексом (на самом деле, это у Яндекса по аналогии с Гуглом) показываются примененные к сайту фильтры. Не все, а как следует из названия, а только наложенные вручную: фильтр за переоптимизацию и фильтр за ссылочный спам.
Сканирование — Ошибки сканирования — здесь вы найдете ошибки внутри сайта, связанные с недоступностью страниц, которые либо удалены, либо сервер вовремя не ответили или выдал ошибку. Таблицу можно выгрузить в архив, но исчерпывающих данных вы все равно не получите. Не знаю почему, но Гугл зажал полный список и отдает только часть. Зато решенные проблемы можно отметить, и они тут же пропадут из статистики.
Вообще в панели Гугла больше вопросов, чем ответов: зачем нам просто циферки, когда гораздо важнее знать, что за ними скрывается? В карте сайта проиндексировано 1000 страниц из 10000, и что дальше? Какие это страницы, почему не индексируются? Не понятно. Гугл очень скуп на информацию для веб-мастеров. Единственное, что можно выгрузить полностью — это беклинки.
Раньше я часто заходил в Серч Консоль, но с появлением Вебмастера 2.0 Яндекса я делаю это все реже и реже.
Программа ComparseR
Думаю, почти все вы, дорогие читатели, знаете мою программу. Программа немного платная, но можно скачать демо-версию и посмотреть дополнительную информацию на промо-сайте (правда, он не обновлялся с 2014 года, но программа обновляется регулярно). Программа разрабатывалась под требования и нужды моей веб-студии. Она позволяет быстро и эффективно находить на сайтах технические ошибки: битые ссылки, страницы имеющие проблемы с индексацией (некорректный мета robots или canonical), дубликаты title и страницы с пустым тегом, дубли заголовки h1, внешние ссылки по типам и еще много чего. Большую часть из перечисленного умеют делать и аналоги, но у Компарсера есть уникальная функция — парсинг поисковых систем и сравнение индекса со структурой сайта.
Далее я буду рассказывать о самых распространенных ошибках на сайтах. Их легко найти, работая с comparser’ом, но вы можете использовать любую другую программу для поиска этих проблем на своем сайте, но я рекомендую скачать хотя бы демо-версию.
Заголовок title и его оптимизация
Title по праву считается самым сильным тегом во внутренней оптимизации, соответственно, ошибки с ним считаются одними из самых грубых. Это очень частая проблема: более 90% всех сайтов, что приходят ко мне на аудит или продвижение, имеют проблемы с дубликатами. Причин много, но среди самых распространенных:
-
Дублирование на страницах листингов в интернет магазинах (постраничная навигация, когда товаров в категории очень много). Это решается добавлением приставки «- страница XX» в title, простановкой тега rel="canonical" с указанием на первую страницу, либо, проще всего, закрытием страниц /*/page, *?page= и т.п. в robots.txt. Страницы пагинации часто дублируют title первой страницы не только в интернет-магазинах, но и на других типах сайтов.
-
Сортировки — бич любого каталога. Хотите отсортировать товары по цене, наличию или просто расположить витрину не списком, а плиткой — пожалуйста. Куча дублей — пожалуйста! Я всегда рекомендую делать сортировки при помощи технологии AJAX, чтобы сортировка товара происходила без перезагрузки страницы и без перехода на другой url. Иногда это сложно реализовать, потому альтернативой послужит использование rel="canonical«, либо совсем простой способ — закрыть параметры сортировки в robots.txt.
-
На сайтах с однотипными товарами возникает много дублей. Например, шины, где для одной модели кроме типоразмеров существуют такие характеристики, как максимальная масса нагрузки или максимальная скорость. Для платьев одного дизайнера и одной модели может быть разный размер, цвет, артикул. Для штор может быть уровень затенения, ширина и длинна шторы. В title по умолчанию добавляется название товара из базы, а в результате куча дублей и вместо всех карточек товара нормально ранжируется только одна, предпочтение которой отдал поисковый робот. Как поисковик смотрит? Одинаковый title, ага. Одинаковый description, ага. Одинаковое название на странице, ага. Значит это дубль, надо выбрать только одну уникальную карточку товара. Решается добавлением уникальных параметров товара в title.
-
В интернет-магазинах часто применяются индексируемые фильтры. Например, по бренду или другой какой-то характеристике. И без должного внимания страницам фильтров присваивается title от родительской категории. А ведь такие индексируемые seo фильтры — это кладезь низкочастотного трафика: фильтры легко масштабировать, настраивать по шаблону, и пусть даже каждая страница принесет по одному посетителю в месяц, благодаря их количеству счет идет на тысячи потенциальных покупателей.
-
Некоторые движки уже насколько изучены (Битрикс, который чаще всего встречается среди наших клиентов), что даже не надо никакой программы, чтобы предположить, где скрываются проблемы. Практика показывает, когда программисты сдают сайт, за настройками для seo никто не следит. Вообще-то они и не должны, ведь разработчики отвечают за продакшн: чтобы выглядело хорошо и работало без проблем. Поэтому прежде чем принимать работу, проконсультируйтесь
со своим лечащим врачомс seo-специалистом, чтобы устранить недочеты на старте.
Как вы могли заметить, большая часть примеров взята от интернет-магазинов — это мой любимый тип сайтов, я очень люблю большие порталы с десятками и сотнями тысяч страниц. Чем больше, чем лучше, тем более классный результат можно показать, исправив допущенные ошибки. Мне очень хочется рассказать о сайтах наших клиентов, но все мое время занимает работа над этими сайтами. Хотя один большой и подробный кейс я все же опубликовал, когда еще работал «наемником» — кейс о сайте по аренде недвижимости. Мне удалось добиться увеличения посещаемости с поиска в 20 раз за 8 месяцев работы. Конечно, это не только исправление ошибок, а долгая и кропотливая работа по изучению ниши и пользовательского спроса, но без идеальной технической базы я бы не смог это совершить!
Заголовок H1 и нецелевое использование заголовков
Еще одним сильным элементом внутренней оптимизации страниц является заголовок H1 — это основной заголовок страницы, который предназначен для посетителей. Распоряжаться этим заголовком уже многие научились и даже до верстальщиков донесли, что основной заголовок страницы должен быть обернут в h1. Поисковые роботы придают значение содержимому заголовка, поэтому нельзя пренебрегать и использованием ключевых слов в нем.
Ошибки тем не менее допускают нередко. Согласно канонам, главный заголовок должен быть один на странице. И точка! Но некоторые верстают в h1 логотип и/или название сайта в шапке — это очень частое явление. Использовать главный заголовок повторно при верстке текста на странице тоже неверно, ведь для этого и придумали h2, h3, h4, h5 и h6 (я рекомендую ограничиться использованием только h2 и h3).
Пример нецелевого использования я привел выше — обернуть логотип в заголовок. Часто при верстке макета заголовки блоков в сайдбаре верстаются заголовками. Это неправильно, заголовки не должны использоваться в сквозных элементах при оформлении дизайна. Заголовки надо использовать только для самого основного контента страницы, иначе они теряют свою эффективность.
Меня часто спрашивают, как формировать заголовки title и H1 и как использовать в них ключевые слова, можно ли прописывать одни и те же запросы в этих заголовках. Как выбрать оптимальную длину и что делать если хочется продвинуть много запросов на одну страницу. Однажды мне надоело отвечать, и я написал подробное руководство по оптимизации заголовков title и h1.
404 ошибки и битые ссылки
Не буду объяснять, почему наличие ошибок внутри сайта плохо. Их надо просто взять и исправить. Они могут появляться по разным причинам: на сайте удаляются неактуальные публикации, при верстке текста контент-менеджер неправильно скопировал ссылки, при смене структуры url не сделали редиректы и внутренние ссылки умерли. Это случается со всеми, поэтому сканировать сайт надо периодически.
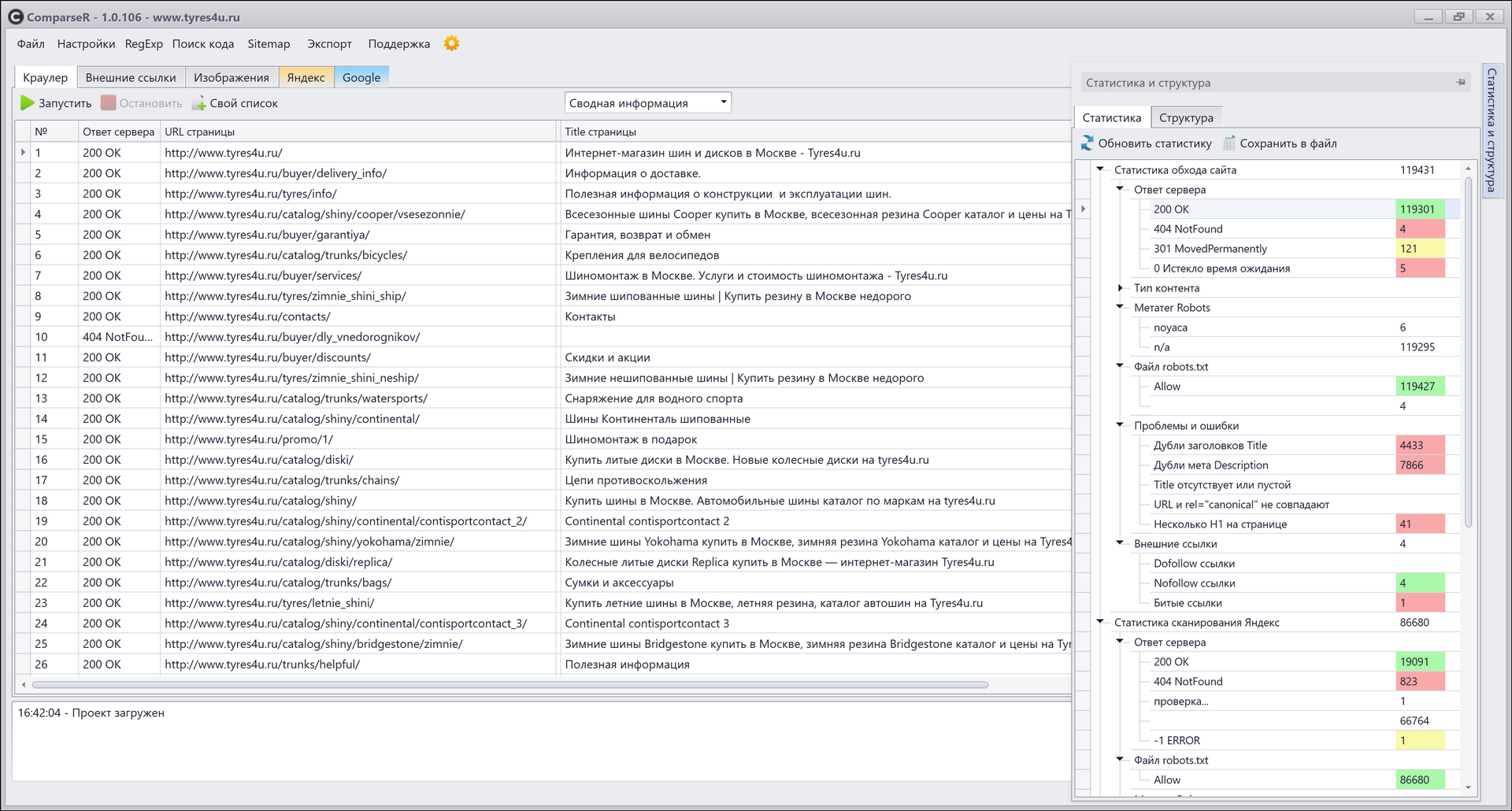
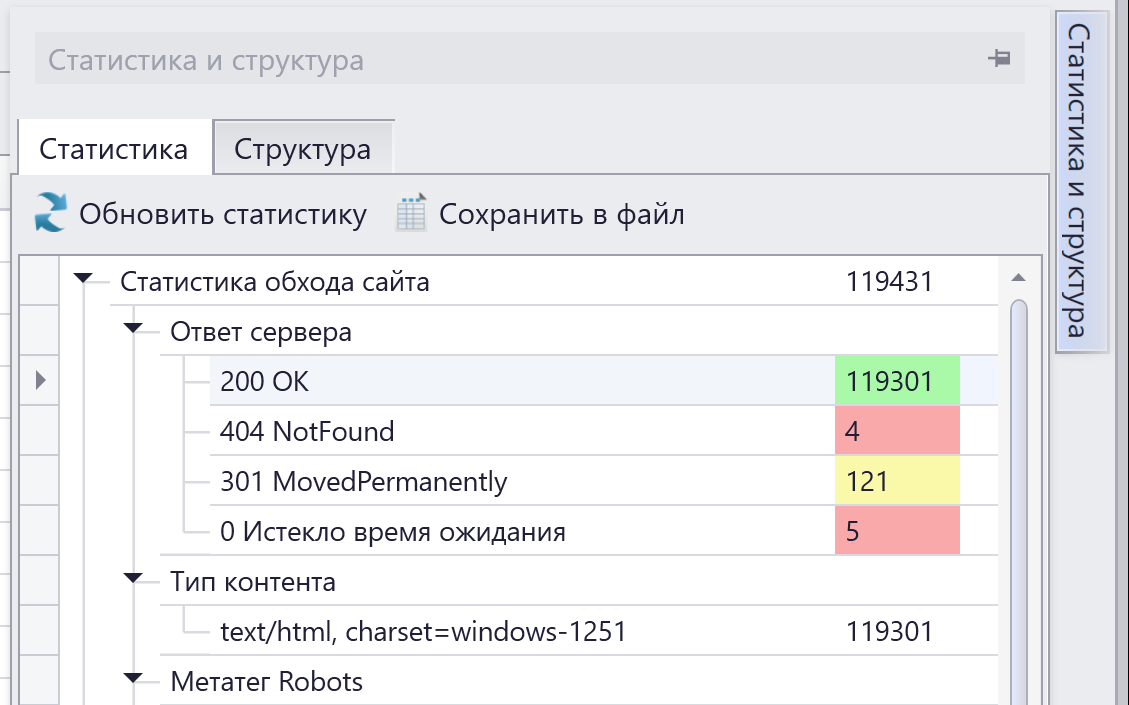
При обходе сайта Компарсер формирует сводку по всем кодам ответа сервера, зеленым отмечено, где все окей, желтым — предупреждение, красным — ошибка.
Нажимаем на интересующую строку, выведется список битых ссылок, а также источник (страница, с которой стоит злосчастная битая ссылка.)
Среди вебмастеров самая известная программа для поиска битых ссылок на сайте — Xenu’s Link Sleuth. Программу нельзя назвать удобной или красивой, самая популярная она лишь благодаря своей бесплатности. По заявлению на официальной странице она работает в Windows 10 несмотря на то, что последнее обновление программы датировано 2010 годом. Сам не проверял, я ей не пользуюсь.
301 и 302 редиректы
Редиректы это и не хорошо и не плохо. Но только в том случае, если вы знаете, как и для чего их надо использовать. Поэтому в программе редиректы помечены желтым цветом — значит надо обратить внимание.
301 редирект — это постоянный редирект, который говорит поисковому роботу, что страница переехала на новый адрес. Навсегда. А значит старый адрес надо забыть и ассоциировать его с новым. При склейке адресов передаются свойства старой страницы. Входящие ссылки, траст и т.д. 301 редирект используется при переезде сайта с одного домена на другой, при смене структуры формирования адресов на сайте, а также для уничтожения дублей страниц.
302 редирект — это временный редирект, который говорит поисковику, что страница лишь временно сменила адрес, и что ее нельзя выкидывать из индекса. 302 редирект на практике используется редко, гораздо чаще он встречается как ошибка, когда должен был использоваться 301 редирект, но по невнимательности программисты поставили 302 редирект (в веб-серверах под управлением *nix систем команда для редиректа по умолчанию использует 302 редирект, если отдельно не указано использование 301 редиректа). Так что, скорее всего, 302 редирект вам не нужен.
Любые редиректы внутри сайта использовать не следует, надо, чтобы все ссылки были прямые и вели сразу на конечную цель. Редирект нужен для того, чтобы не потерять внешние ссылки и связи, ведь на внешних источниках мы не можем вручную исправить ссылки.
Никого не удивлю, сказав, что я уже написал огромный пост-руководство о том, зачем нужны редиректы, как их правильно использовать и прописывать. Подробно разобраны частые случаи, а в довесок еще 750 комментариев обсуждений и разбора частных случаев от читателей.
Исходящие ссылки — что с ними делать?
Многие переживают из-за внешних ссылок на сторонние сайты. Типа вес страниц «утекает», поисковики могут хуже относиться к сайтам с множеством внешних ссылок и т.д. На счет внешних ссылок должны переживать только те, кто занимается продажей ссылок в биржах, потому что могут не пройти по фильтрам. А поисковики относятся негативно только к продажным и нетематическим ссылкам, а если ссылки ведут на авторитетный сайт или документ, который дополняет написанное на странице, — так за что тут наказывать?

Для совсем уж одержимых (таких как я), чтобы все было идеально и красиво, могу посоветовать просканировать все внешние ссылки с сайта и закрыть их в nofollow, а все битые ссылки на внешние сайты либо удалить, либо исправить. Вот типичная карта внешних ссылок на инфосайте от года и старше:
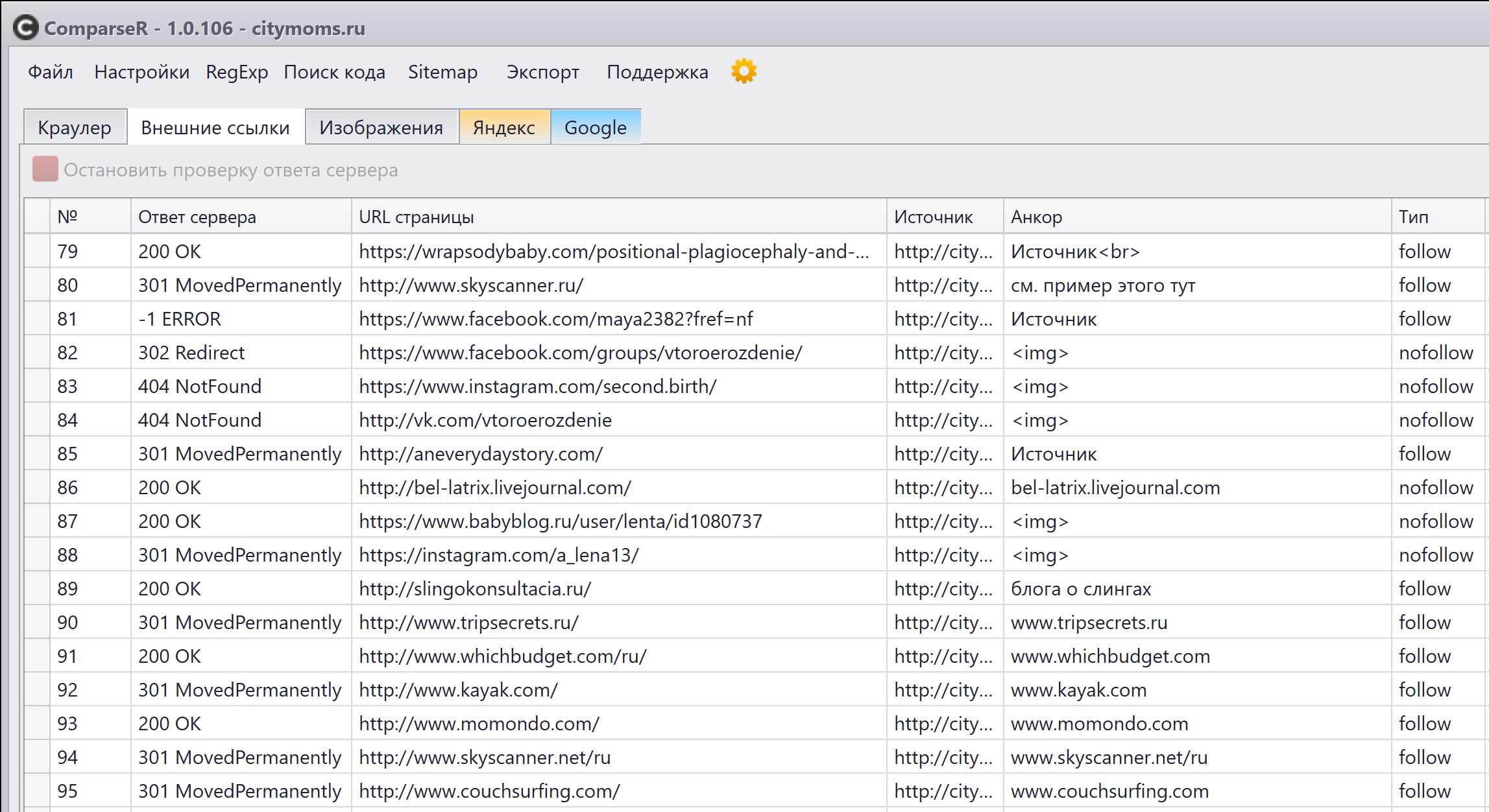
Обращаю ваше внимание на то, что несколько лет назад принцип действия атрибута nofollow для ссылок изменился. Раньше использование этого атрибута пресекало «утекание» веса со страницы по ссылке, а теперь все иначе — вес все равно утекает, но не достигает той страницы, на которую ведет ссылка, то есть попросту испаряется. Таким образом атрибут nofollow лишь говорит поисковому роботу, что ссылку не надо учитывать, передавать по ней вес и page rank.
Для тех, кого пугает сама мысль, что с сайта куда-то «утекает» какой-то вес, тоже есть решение — скрывать ссылки при помощи скриптов. Можно сделать так, чтобы сама html конструкция ссылки на странице отсутствовала, и роботы ссылку не видели, при этом для пользователя эта ссылка будет видна и будет активна.
Google PageSpeed Insights
Очень полезный и простой инструмент, который покажет вам две важные вещи: удобство для пользователей мобильных устройств и скорость загрузки сайта с оценкой по
Про мобильную версию или адаптивную верстку для мобильных пользователей я молчу, тут и ежу понятно, что надо брать и делать.
Если ваш сайт находится в красной зоне (ниже 50 балов), я вам советую обратить внимание на 2 самых важных пункта, исправление которых повысит и баллы, и увеличит быстродействие сайта для реальных посетителей: «Используйте кеш браузера», «Включите сжатие». Разверните эти пункты и увидите перечень адресов, если там есть ресурсы с вашего домена, значит надо исправлять. Обычно это решается корректной настройкой движка сайт, установкой модуля, либо добавлением нескольких строк в .htaccess. Если вы мало что поняли из сказанного, попросите программиста, он вам за пару часов все сделает.
Кстати, почему достижение 100 баллов является задачей нетривиальной? Потому что среди ресурсов, требующих оптимизации, есть счетчики Метрики и Гугл Аналитики, сторонние JS, особенно скрипты соцсетей, необходимые для отображения виджетов или кнопок. Иногда исправить это просто невозможно, а главное, что и быстродействия не добавит (современные скрипты подгружаются асинхронно)!
Индексация сайта: изучение и настройка
Выше мы говорили о том, как заставить страницы лучше ранжироваться, но не затронули вопрос, как заставить страницы лучше индексироваться. А ведь индексация идет прежде, чем ранжирование, соответственно, нет смысла оптимизировать непроиндесированную страницу.
Проблемы с индексацией встречаются чаще всего на больших сайтах: чем больше сайт, тем больше проблем. Сейчас расскажу про настройку сайта для хорошей индексации.
Настройки индексирования внутри сайта
Первое, что нужно сделать — это запретить для индексации все технические страницы, которые не представляют интереса для поисковиков и не предназначены для привлечения трафика. Лучше всего запрещать страницы от индексации при помощи метатега robots, вместо файла robots.txt. Google, не смотря на запреты в robots.txt, все равно добавляет страницы в индекс, но их содержимое не ранжирует. Однажды я уже подробно описывал, как и почему это происходит.
Так же стоит исключить очень похожие страницы и дубли (об этом мы уже говорили выше). Если на сайте есть одинаковые или похожие страницы, поисковым роботам будет сложно определить нужную релевантную страницу, а мы не будем понимать, куда приземляются посетители, наши ожидания не совпадут с реальностью и это, поверьте, большая проблема. Бывает, что поисковикам неохота выбирать правильную страницу из набора похожих и они предпочтут вообще не ранжировать ваш сайт, а отдать предпочтение другим сайтам, где такой проблемы нет.
Есть такой термин — каннибализация — негативное влияние использования одних и тех же ключевых слов на разных документах сайта. Вы заставляете поисковые системы выбирать, но что еще хуже, вы запутываете посетителя и теряете контроль над его поведением на сайте, ухудшаете поведенческие факторы и сами не знаете, какую страницу продвигать. Золотое правило — под один ключевой запрос (группу схожих ключевых запросов) должна быть только одна единственная релевантная страница. Если на вашем сайте есть такая проблема, используйте редирект на приоритетную страницу, либо пропишите canonical.
Кроме закрытия ненужных страниц важно не ссылаться на эти самые ненужные страницы. На сайте не должно быть внутренних ссылок на закрытые страницы, потому что поисковики будут все равно на них рваться. Для фанатов «веса» страниц стоит сказать, что из-за таких ссылок утекает вес сайта в никуда — голактеко опасносте, господа! В противном случае статистика сайта в панелях вебмастера будет замусориваться отчетами о страницах, запрещенных к индексации. Лично меня эта статистика угнетает, мешает изучать реально существующие проблемы, и я постоянно думаю, что что-то пошло не так.
Слышали что-нибудь про «краулинговый бюджет»? Это некий отведенный поисковыми роботами лимит страниц для вашего сайта, которые робот обойдет и возможно добавит в индекс. И чем больше ненужных страниц встретится на пути, тем меньше полезных страниц будет проиндексировано. Нередки случаи, когда на сайте страниц много, а находится в индексе в десятки, сотни, а то и тысячи раз меньше страниц. Иногда большим сайтам не хватает этого самого бюджета, а иногда до страниц банально очень сложно добраться. Обязательно создайте xml и html карту сайта, настройте сервер, чтобы он максимально быстро отвечал за запросы.
И не забывайте про перелинковку, но такую, чтобы была полезна посетителям. Для информационных сайтов это может быть блок ссылок на публикации из той же категории. Ссылки на публикации по теме из тела статьи — аля Википедия. Для интернет-магазинов прекрасно работают блоки ссылок на похожие по характеристикам товары и ссылки на сопутствующие товары. Все это принесет пользу не только посетителям вашего сайта, но и позволит поисковикам лучше и быстрее индексировать полезные страницы.
Для своих инфосайтов я эффективно применял кольцевую перелинковку — это когда одна публикация имеет блок ссылок на 5 предыдущих публикаций сайта, и так по кругу. Каждая публикация ссылается на соседние, в итоге все публикации на сайте получают одинаковое количество внутренних ссылок, никто не остается обделенным.
Эта методика прекрасно себя показала, и мне удалось добиться 100% индексации на своих сайтах. Для CMS DLE, которую я использовал, был написан специальный модуль кольцевой перелинковки LinkEnso (позже был выпущен LinkEnso PRO — платная версия с расширенным функционалом), который стал настоящим хитом: десятки тысяч скачиваний и сотни покупок, и это при том, что модуль валяется на каждом углу бесплатно.
Технология реально рабочая, я масштабировал ее на коммерческие сайты, и это дало эффект, так что берите на вооружение!
Изучение поискового индекса сайта
Когда я только думал над созданием программы ComparseR, ключевой особенностью я видел возможность парсить индекс поисковой системы и сравнивать с тем, что есть на сайте. Ценность заключалась в том, чтобы найти непроиндексированные страницы и пакетно загнать их в аддурилку. Но до меня быстро дошло — ценность в том, чтобы найти то, что на сайте отсутствует.
Понимаете, о чем я? Вот к примеру, на ваш сайт залили дорвей, как вы об этом узнаете? На него не оставят внутренних ссылок, он никак не будет связан с вашей CMS и никак не повлияет на работу сайта. Бывают случаи, когда злоумышленники берут и копируют частично дизайн вашего сайта вместе со счётчиками для страничек на своем дорвее. Дорвей выстреливает и на него начинает идти трафик. В Метрике вы увидите всплеск посещаемости по совершено невообразимый для вас запросам (почему-то такое часто возникает на Битриксе, я несколько раз становился свидетелем «взрыва» посещаемости на клиентских сайтах именно на Битриксе). Но что если счетчик не скопировали, сколько времени пройдет пока вы заметите? Вы заметите это когда ваш сайт погибнет вместе с дорвеем. Дорвеи горят ярко и живут недолго, они состоят из большого количества страниц, каждая из которых заточена под один поисковый запрос и сильно переоптимизирована. Если размер вашего сайта сильно меньше, чем размер дорвея, когда поисковик начнет «выпиливать» дорвей, ваш сайт уйдет на дно вместе с ним, как незначительная небольшая его часть.
Чтобы вовремя заметить беду, надо периодически парсить поисковый индекс вашего сайта. С этой задачей прекрасно справляется Компарсер — показать все, что скрыто:
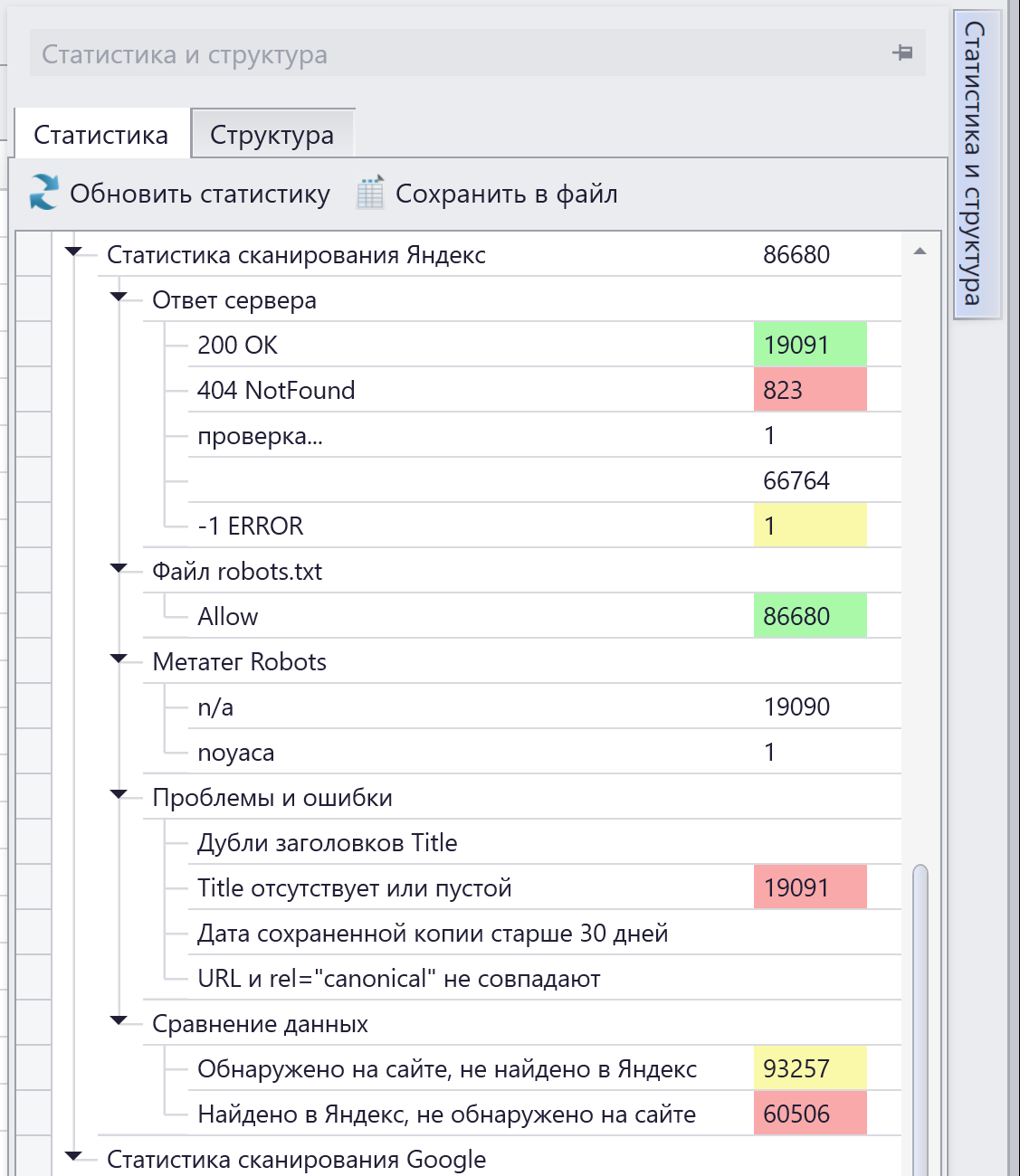
Страницы, которые нашлись на сайте, но отсутствуют в индексе, надо заставить проиндексироваться. Раньше, когда была старая версия Яндекс.Вебмастера, существовала аддурилка — туда можно было поштучно отправлять любые адреса и они становились в очередь на индексацию. Вручную это делать было нереально (вставлять адрес, вводить капчу), но Компарсер это автоматизировал. Только вот лавочку прикрыли, аддурилку Яндекс убрал. Теперь единственным вариантом заставить страницы индексироваться — это те приемы, о которых я рассказывал в предыдущем блоке.
В Гугле лавочку с добавлением страниц не закрыли, но защитили — раньше там была классическая рекапча, которую индусы щелкали на раз, теперь там стоит новомодная штуковина, заставляющая сопоставлять картинки по смыслу, если вас заподозрили в «роботизме». В итоге автоматическое добавление страниц на индексацию обломилось везде :(
Все непросто — это когда найдены страницы в индексе поиска, а на сайте при обходе почему-то не обнаружены. Надо понять, что это за страницы и почему они не найдены при обходе сайта:
-
Удаленные страницы, 404 Not Found. Бывает, что товары из магазинов пропадают, записи снимаются с публикации. Соответственно, на сайте этих страниц уже нет, и ссылок на них тоже. А в индексе эти страницы могут остаться и выдавать ошибку. Надо взять список этих страниц и закинуть в инструмент пакетного удаления из индекса. Это еще работает для Яндекса и Гугла.
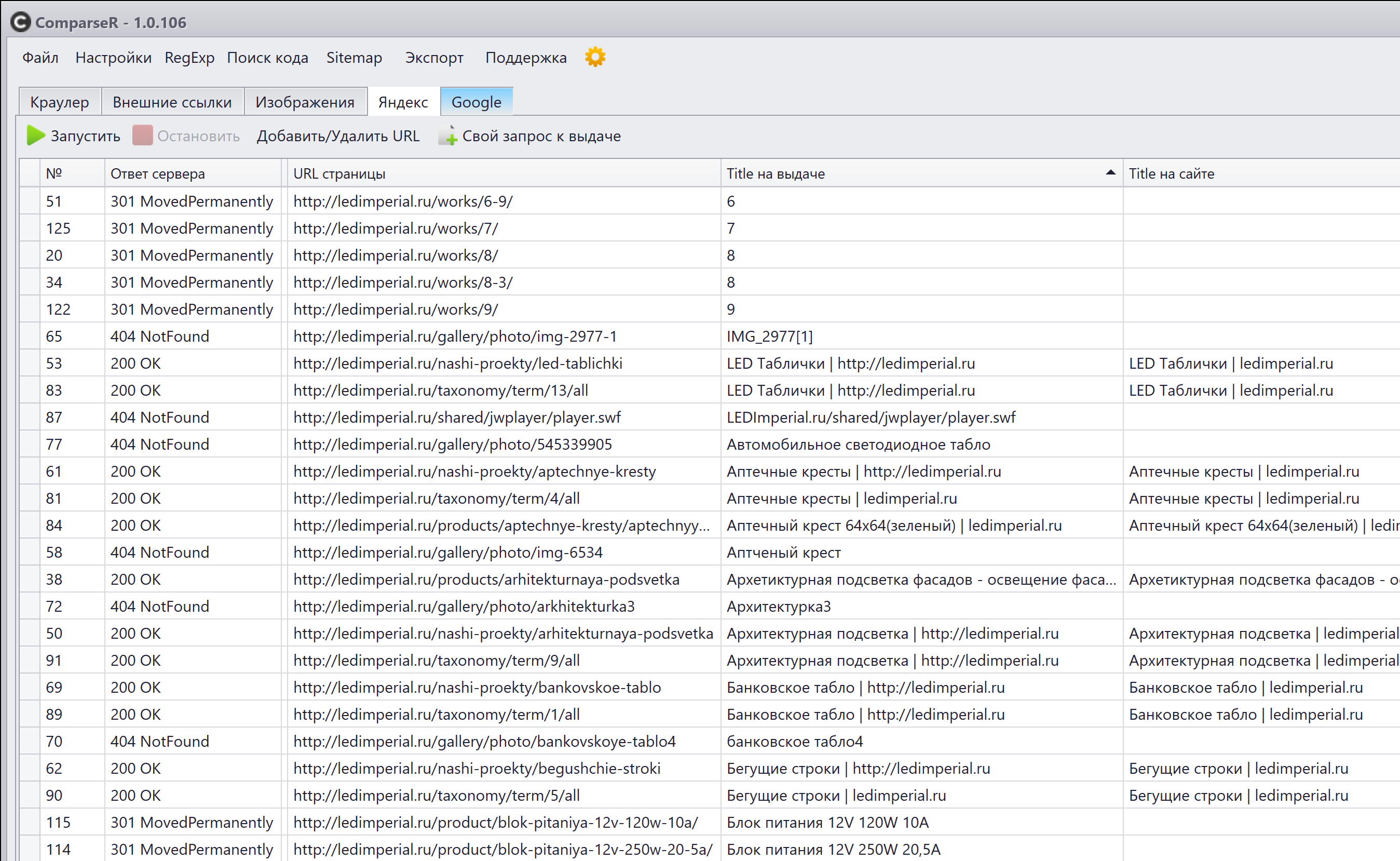
-
Страницы товаров, запрятанные далеко в каталоге. Если в интернет-магазине много товаров, а в категориях присутствует постраничка, которая закрыта от индексации, чтобы избежать дублирования, может случиться так, что до многих товаров невозможно добраться. И добраться не может не только программа-краулер, но и поисковые роботы, так что такие страницы из индекса со временем выпадут, а нам этого не надо. Разберитесь с перелинковкой.
-
Дубли! Откуда они могут взяться? Параметры! Вы ведете контекстную рекламу и используете utm-метки, люди переходят по ссылкам с этими метками, и они индексируются. У вас на сайте есть партнерская программа, в которой любой партнер подставив в url страницы в конце параметр ?PartnerId=123 привлекает рефералов. Параметры могут взяться из самых неожиданных мест, а вы можете об этом и не знать. Страницы с параметрами полностью дублируют аналогичные страницы без параметров, но индексируются наравне с ними и являются дублями, портя карму вашему сайту и отдельным страницам. Такие дубли надо решать при помощи rel="canonical«.
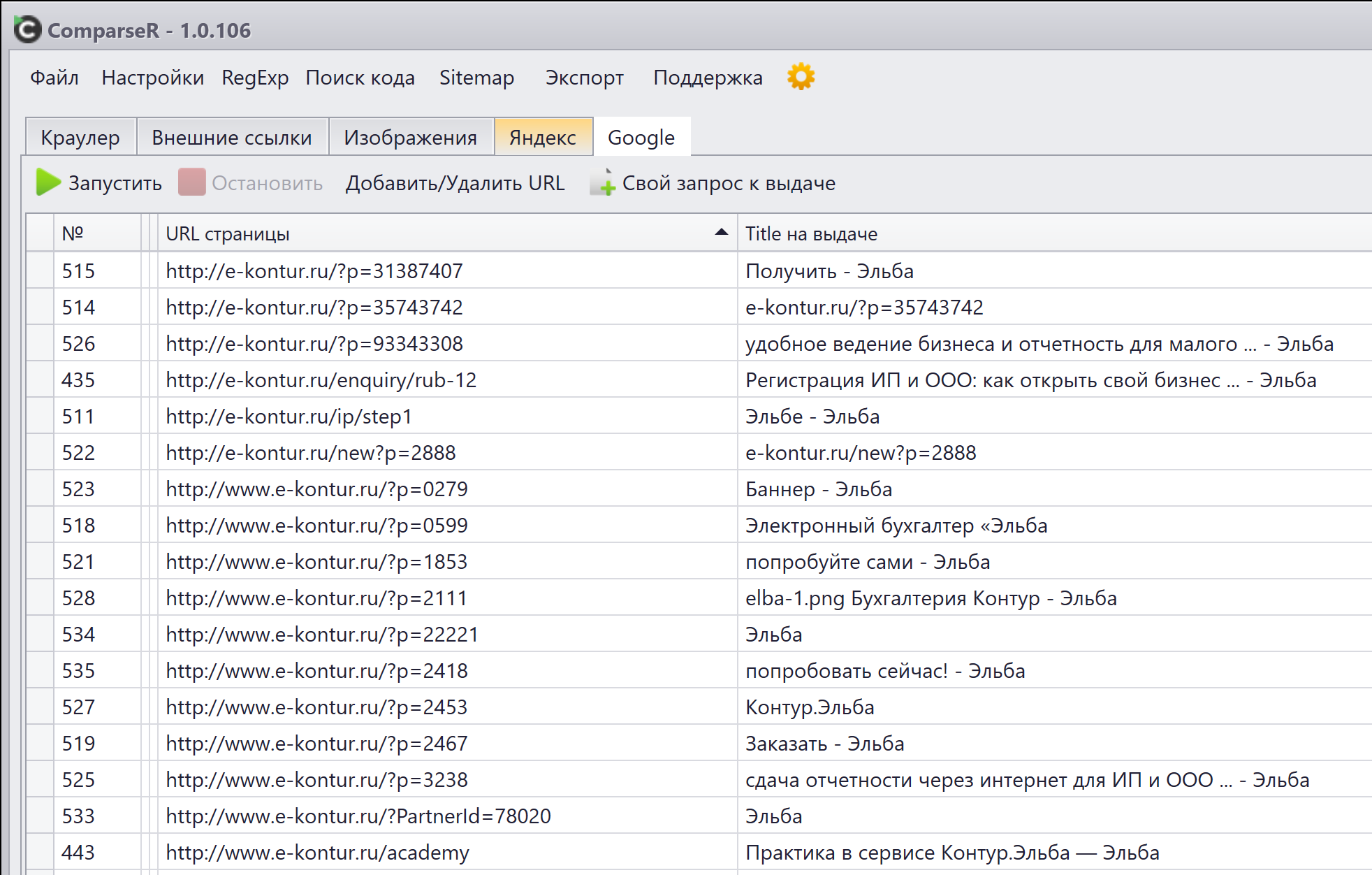
-
Дорвеи. Я про них уже говорил, но теперь покажу, как это выглядит. Краны, подъемники, вакансии компаниии... А потом бах — простата, виза в польшу, атанасян, бацзы! Что? О_о
В данном примере дорвей уже удалили, но в индексе он еще болтается:
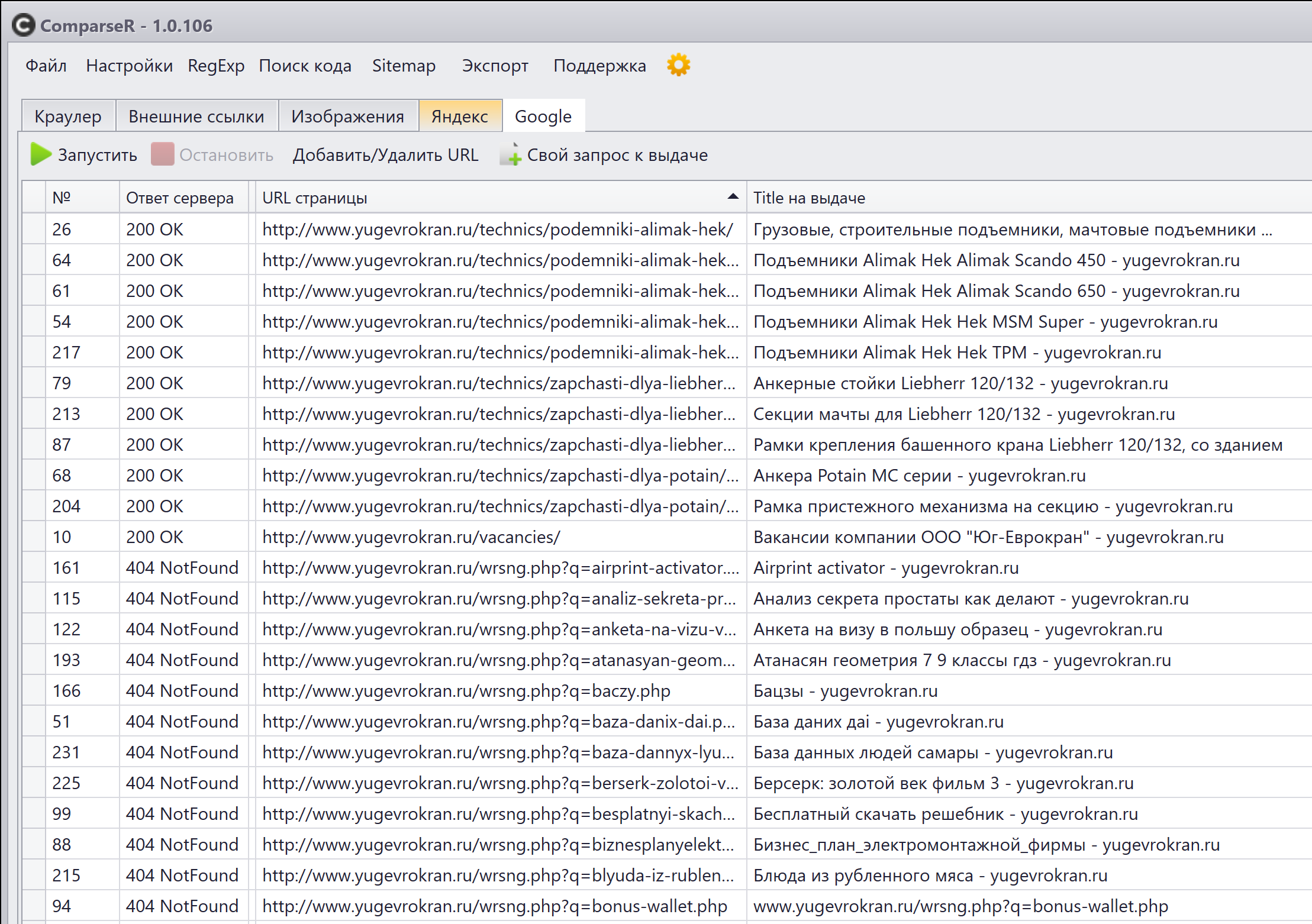
Все это барахло: несуществующие страницы, ошибки и прочее надо удалять с сайта, закрывать от индексации и пакетно удалять из индекса. Благо, такая возможность есть, автоматизация реализована, а лавочку пока не прикрыли.
Я уже упоминал, что в новой панели вебмастера Яндекса сделали возможность выгрузить любые данные архивом для изучения. Компарсер мы научили выкачивать архив, забирать оттуда проиндексированные страницы и добавлять в таблицу. Таким образом можно обойти ограничение поисковой выдачи на 1000 результатов и получить 100% точный результат индексации сайта. Это облегчает задачу многократно, а вот в Гугле есть проблемы, там не только в панели вебмастера скудные данные, но и в выдаче — получить все проиндексированные страницы невозможно, даже если их совсем небольшое количество. Зато наличие и разнообразие проблемных страниц в индексе, даже закрытых от индексации, компенсирует этот недостаток.
MegaIndex.com
MegaIndex.com (обратите внимание: .com, а не .ru) прекрасный инструмент для внешнего аудита любого сайта. Внутренний аудит сайта он не делает, ошибки внутри не покажет, но зато покажет видимость сайта по запросам, какие ссылки на него ведут, делается ли контекстная реклама и по каким объявлениям, и еще много-много-много всяких полезных штучек. Сервис развивается, там появляются новые инструменты, некоторые из которых уникальны в своем роде и недоступны даже в других платных сервисах. И это, не поверите, — все совершенно бесплатно.
Когда приходит сайт на аудит или продвижение, я пользуюсь следующими возможностями:
-
Общая информация — тут и правда общая информация: видимость сайта в органике, видимость в контексте, количество внешних ссылок, источники трафика, ключевые слова и т.д. Важный момент! Данные по трафику и источникам не корректны для регионов, для Москвы и еще десятка городов все четко, а для Краснодара и городов поменьше все плохо. Количество трафика даже для Москвы нельзя считать достоверным в абсолютных значениях, а вот в относительных вполне. То есть, если на вашем сайте показывается 100 переходов с поиска, и 50 с контекста, это может быть далеко от реальности, тоже относится и к конкурентам. Но если сравнивать данные относительно, то все почти совпадает.
-
Внешние ссылки. Сами знаете, со ссылками шутки плохи последнее время, надо быть очень внимательным. Об этом я совсем недавно писал и говорил подробно. Поэтому лучше сразу понять, покупаются ли ссылки на сайт, с какими анкорами, есть ли риск наложения фильтра. А заодно посмотреть, как ведут себя конкуренты, и можно ли продвинуть сайт в конкретной тематике без ссылок.
-
Анализ сниппетов. Этот инструмент мне нравится тем, что на одной странице можно быстро посмотреть, какие сниппеты для разных страниц и запросов показываются на выдаче. К техническим моментам это не относится (ну, разве что, вместо описания показывается какая-нибудь белиберда), но по части CTR на поиске очень даже полезно!
-
Исходящие ссылки. Некая быстрая альтернатива сканированию сайта программой. Если сайт проиндексирован сервисом, то можно изучить исходящие ссылки, куда они ведут, спамные ли они, точно ли они размещены по доброй воле или это происки злоумышленников.
По Мегаиндексу можно вообще отдельный пост написать, каким инструментом и для чего пользоваться. Но это уже не для аудита, а для аналитики и будущего продвижения — определить основных конкурентов, узнать по каким запросам они продвигаются и находятся в топе, какими ссылками закупаются и т.д.
Спасибо вам за внимание, друзья!
До встречи!

Мария Тюхтина
Руководитель отдела интернет-маркетинга агентства Bquadro
Руководитель отдела интернет-маркетинга агентства Bquadro
Обычно аудит сайта можно условно разделить на три блока: SEO-аудит сайта, технический аудит и аудит юзабилити (удобства использования). «Условно» именно потому, что эти части между собой взаимосвязаны. С одной стороны, проведение аудита — необходимое условие успешного продвижения сайта.
С другой стороны, когда владелец сайта пытается самостоятельно провести аудит, из этого обычно ничего путного не выходит. У нас были случаи, когда клиент использовал автоматизированные сервисы для проведения аудита и буквально засыпал нас письмами с вопросами наподобие: «Почему на страницах пейджинации не прописан тег noindex?». Мы были вынуждены часами объяснять, что по нашей практике лучше использовать rel canonical. Поэтому я немного предвзято отношусь к бесплатным сервисам с претензией на профессиональный аудит.
У нас есть формализованные чек-листы для SEO-специалистов, где некоторые пункты проверяются обязательно вручную. Например, наличие и содержание файла robots.txt, корректность настройки редиректов с неоснового зеркала домена на основное, анализ списка наиболее посещаемых страниц и сопоставление этого списка с наиболее приоритетными для заказчика страницами сайта и т.д.
Из автоматизированных помощников могу назвать следующие: различные «пауки» — PageWeight, Screаming Frog; сервисы для сравнения с конкурентами SpyWords, Megaindex; для проверки корректности ответа сервера bertal.ru, для проверки валидности кода — validator.w3.org.
Конечно, аудит нужно проводить не однократно, а регулярно по мере развития сайта. Есть моменты, проверку которых мы автоматизировали. Например, если на сайте пропадут или изменятся счётчики статистики, исчезнет файл robots.txt, сайт не будет доступен, — наша система моментально отреагирует и пришлёт тревожное письмо на почту отдела поддержки и продвижения. Это может показаться банальным, но здорово спасает, если что-то сломается, например, во время отпуска SEO-специалиста или если клиент без предупреждения решит внести критичные изменения на сайт.
Как бы ни хотелось всё автоматизировать, до сих пор нет сервиса с волшебной кнопкой «проверить всё», который бы дал обзор и оценку всех индивидуальных особенностей сайта. SEO-специалист по-прежнему выполняет огромный пласт работ: просматривает сайт через вебвизор, анализирует карты скроллинга и кликов, смотрит объём трафика по брендовым запросам, тестирует функционал, определяет перспективы развития сайта и пути достижения поставленных целей.
Чтобы не пропустить новые материалы на CMS Magazine,
подпишитесь на наши каналы в MAX или Телеграм
подпишитесь на наши каналы в MAX или Телеграм
 Канал в MAX
Канал в MAX Канал в TG
Канал в TGИщете исполнителя для реализации проекта?
Проведите конкурс среди участников CMS Magazine
Узнайте цены и сроки уже завтра. Это бесплатно и займет ≈5 минут.
похожие статьи
Вакансии
на workspace.ruОфис-менеджер
Брендинговое агентство DepotМосква
Смм-менеджер / помощник маркетолога
GetOfferУдаленно30,000 — 50,000 ₽
SEO-специалист
QLANУдаленно
Senior UX Researcher
F`ARTУдаленно
Специалист по маркетингу
Смотреть всеясалтаяУдаленно30,000 — 60,000 ₽
Наверх
Агентства
Проекты компании Proactivity Group




© 2006-2026 CMS Magazine
Электронное СМИ. Эл № ФС 77-32705
18+
Руководитель отдела интернет-маркетинга компании R52.RU
Спасибо Александру за хороший материал. Всё написано понятным и доступным языком. Думаю, что это один из лучших материалов по аудитам, встречавшихся мне за последнее время.
Вся техническая часть опирается на применение программы ComparseR, которая хоть и платная, но своих денег стоит, т.к. аналогов, которые бы сравнивали поисковый индекс с реально существующими страницами на сайте, ещё нет.
Единственное, что хотелось бы дополнить: в версии 2.0 ЯндексВебмастера аддурилку заменили разделом «Переобход страниц», который позволяет добавить на индексацию 10 страниц сайта в сутки. Конечно, не так много, как хотелось бы, но это пока что лучше, чем ничего.